
Расшифровка семинара Юлии Бареевой (Xperience AI), который состоялся в апреле 2020 года. Видеоверсия доступна для просмотра на нашем youtube-канале.
Как устроена CUDA?
Сегодня я расскажу о программировании на CUDA. Я думаю, это полезно для понимания того, что же творится за PyTorch, и как все устроено. Я буду рассказывать о том, что меня особенно впечатлило из интенсива, который вел Перепелкин Евгений Евгеньевич, профессор МГУ. Мы целую неделю занимались программированием на CUDA и очень подробно рассматривали архитектуры, кодили и так далее.
Весь материал я проверяла на своей родной карточке – NVIDIA® GeForce® RTX 2070 SUPER™, работающей на базе архитектуры Turing. Давайте для начала на нее посмотрим.
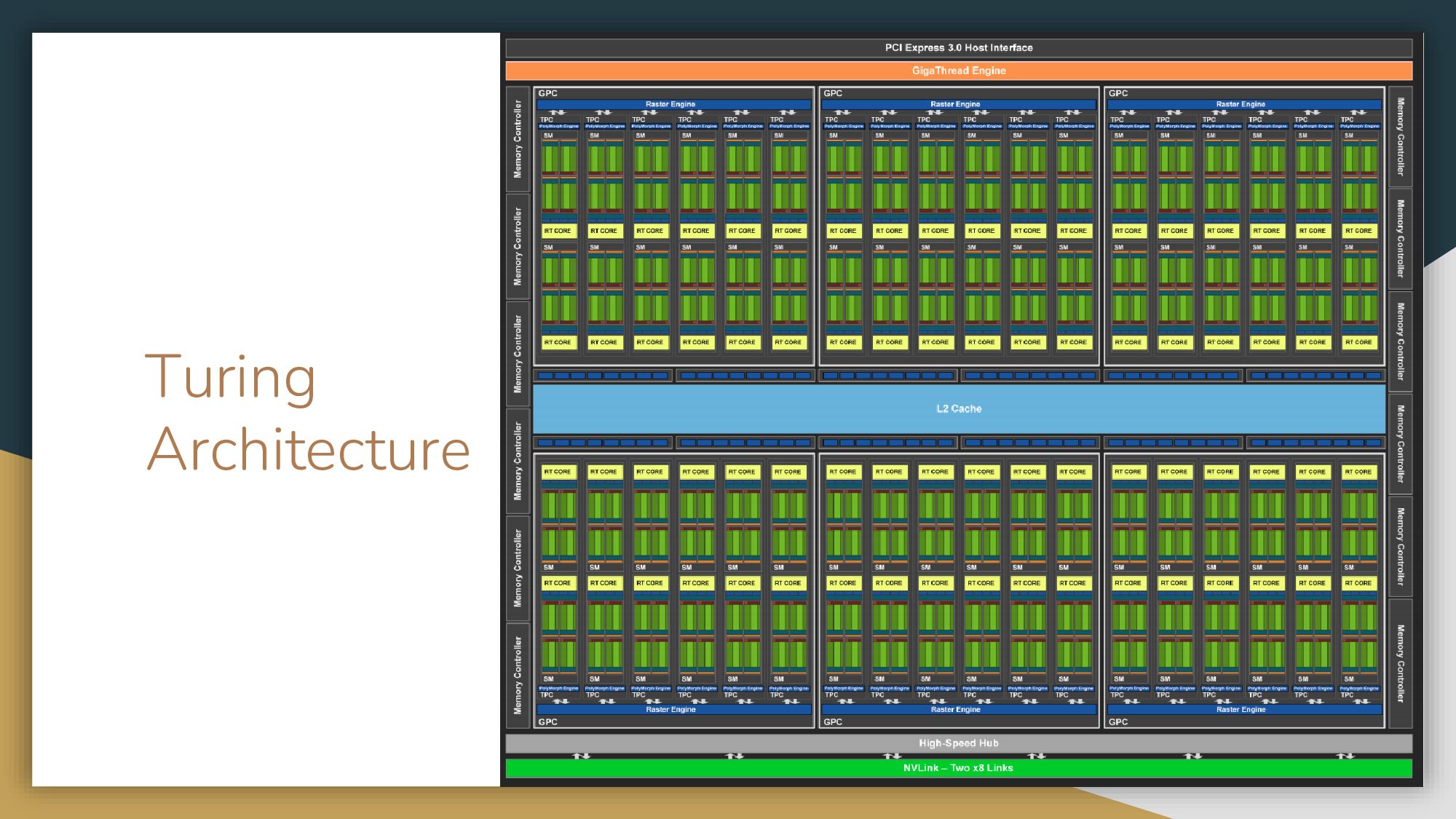
На схеме видны некоторые вычислительные ядра, кэш, память и так далее. Больше всего нас интересует сам стриминговый процессор – это такой блок вычислительных ядер, он называется SM (Streaming Multiprocessor). Если мы разберемся, как он устроен, мы поймем, как и почему все работает и как правильно писать программы. Здесь вы видите один основной блок, разделенный на блоки поменьше. Каждый SM блок содержит 64 ядра для вычислений в INT32, 64 ядра для вычислений в FLOAT32 и тензорные ядра, которые мы сегодня рассматривать не будем.
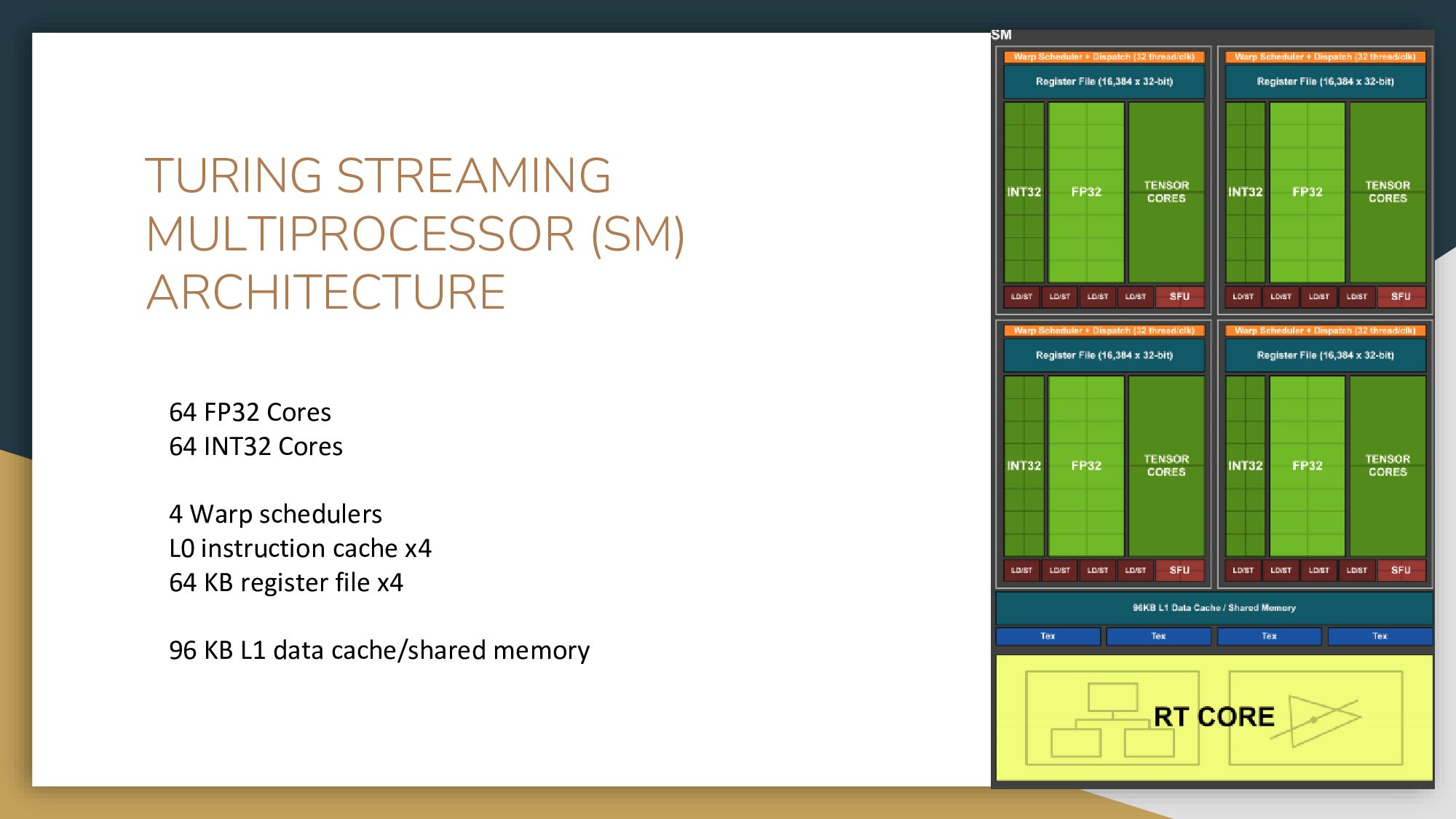
Оранжевая полосочка – это схематичное изображение планировщика: он распределяет задачи по ядрам. Темно-красные прямоугольники внизу обозначают блоки, которые отвечают за обращение к данным. У каждого из четырех блоков есть свой файловый регистр (это очень быстрая память, гораздо быстрее, чем глобальная память) и свой L1 кэш. Один блок SM – один L1 кэш на всех. Очень маленький блок SFU (Super Function Units) – это блок, который считает предопределенные функции типа косинусов, синусов. Раньше он занимал больше места, потому что это было популярно и экономило людям много времени.
В этой архитектуре L1 кэш и разделяемая память делят одну и ту же память – и это очень быстрая память, естественно, быстрее глобальной. Еще есть текстурные ядра, но сейчас ими редко пользуются. Они использовались раньше для обсчета текстур в 3D-играх. Я пробовала на них считать – никакого разительного прироста я на своей современной карточке и своих задачах не заметила. Также мы видим ядро для трассировки лучей – о нем мы сегодня говорить не будем.
Пишем программу на CUDA и запускаем ее на GPU
Для начала вам нужно поставить драйверы для своей конкретной видеокарты, затем установить CUDA Toolkit (если вы по каким-то причинам не установили его вместе с драйверами). Потом написать свой первый файл с расширением .cu и скомпилировать NVCC компайлером – он поставится с CUDA. В старых версиях приходилось отдельно компилировать CUDA и свой код на С++ – сейчас NVCC умеет все вместе. Просто скармливайте ему свои файлы, которые используют библиотеки из CUDA, и он все прекрасно компилирует.
Каков же основной признак программы на CUDA? Основное, что мы пишем – это Kernel, функция ядра. Даже в тех же TensorRT и PyTorch где-то глубоко-глубоко кто-то написал за вас Kernel функции.

Теперь о том, как написать свою kernel-функцию и как она выглядит. Сначала мы ставим спецификатор: _ _global_ _ - если функция должна вызываться на CPU, но исполниться на GPU, _ _host_ _ - если функция вызывается и выполняется на CPU, и _ _device_ _ - если функция вызывается и выполняется на GPU соответственно. Из одних kernel-функций можно вызывать другие, так называемые дочерние. А так же эти спецификаторы можно комбинировать. Далее мы пишем название функции и в тройных угловых скобочках указываем четыре параметра. Последние два из них необязательные (nShMem, nStream). Это количество разделяемой памяти в потоке и собственно сам поток, мы попозже об этом поговорим. Давайте пока остановимся на первых двух (nBlock, nThread). Это количество блоков и количество тредов.
Вернемся на SM. У нас есть размерность задачи – например, вектор с миллионом элементов. Вы понимаете, что у вас есть несколько вычислительных ядер, и весь миллион выгоднее разбить и обсчитывать частями. На один SM приходят несколько блоков вычислений. Их количество зависит от архитектуры, планировщика и так далее. Давайте рассмотрим абстрактный пример.
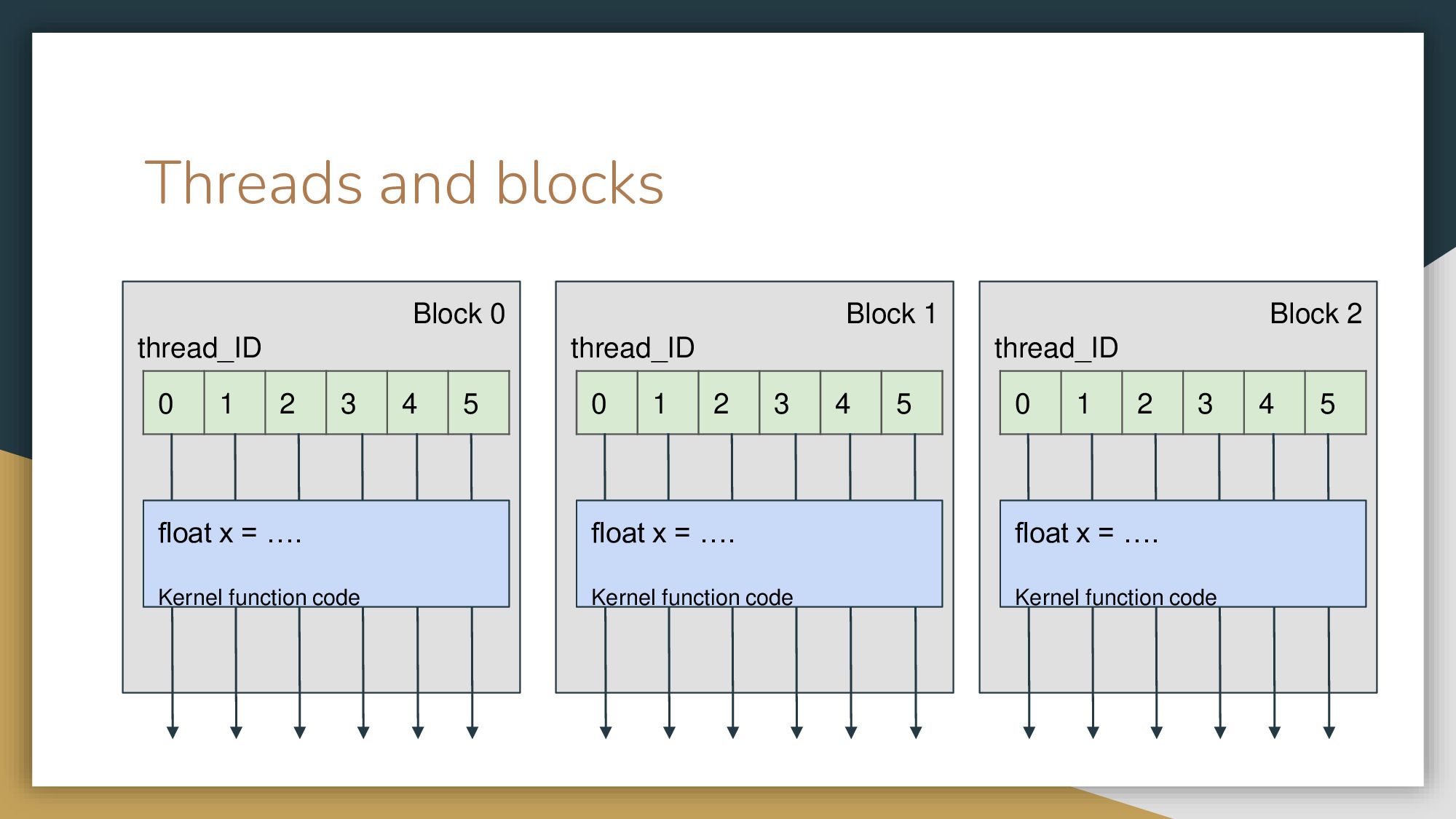
Пусть каждый SM получает на вход, допустим, три блока (обычно это число выше). В каждом блоке у вас будут запущены несколько нитей, одно и то же количество. Каждая нить запустит код вашей Kernel функции. Таким образом мы будем знать, в каком блоке и в каком треде мы находимся и в зависимости от этого просто будем брать кусок данных, который мы, как программисты, решили выполнять на этом блоке. Планировщик сам решит и отправит каждую нить вычисляться на своем вычислительном ядре. На современных карточках нитей либо 512, либо 1024 – больше просто физически не влезает. Но количество блоков у вас может быть каким угодно, просто если первые сто тысяч блоков не влезли на карточку, она выполнит сначала первые 50 000, потом вторые.
Пример Kernel функции
Давайте рассмотрим на примере и напишем свою первую Kernel функцию, которая будет вычислять сумму синусов. Я взяла функцию посложнее, чтобы немного нагрузить GPU, потому что иначе вычисления прошли бы слишком быстро и эксперимент не был бы показательным. Мы пишем Kernel функцию, которая будет просто вычислять каждый элемент по такой формуле. У нас есть входной массив чисел a, входной массив чисел b, и мы хотим записать данные в выходной массив чисел c. Каждое число ci будет просто вычисляться по этой формуле. Каждая нить один раз просто посчитает эту сумму, ее задача – сложить один раз сто чисел. Мы должны определить номер нити, в которой мы находимся. Умножаем ее на количество блоков – это и есть номер нити. Если мы во втором блоке, значит, прошло уже 10 нитей до нас, соответственно мы должны к 10 прибавить номер текущей нити. (idx = blockIdx.x * blockDim.x + threadIdx.x) Так мы возьмем и вычислим номер текущей нити как номер. Обычно мы вычисляем в двумерном массиве.

Может произойти так, что размер массива нацело не поделился на количество нитей или количество блоков и у нас остался хвостик, который не влез. Например, у нас на блоке 512 нитей, а хвост массива занимает всего 300 нитей. Чтобы нам не промахнуться мимо памяти, мы просто ставим if и по индексу нити выполняем все эти вычисления. Это самая простая Kernel функция, которую нужно вставить в свой файл, называемый .cu, запустить – и все пойдет считаться на GPU.
Посмотрим, что происходит в функции main. Здесь я взяла 512 нитей. Количество блоков я вычислила исходя из размера задачи: у меня массив размером 500 000 на 512, я просто поделила на количество нитей в блоке. Далее происходит выделение памяти – для этого используется специальная специальная функция cudaMalloc. К сожалению, хотя С++ уже давно ушел от всяких маллоков, аллоков и так далее, CUDA все еще занимается этим, хотя уже появился Cuda Thrust с векторным интерфейсом. Мы выделяем память под эти три массива – для a и b, которые будем складывать и для c – это результат. Далее инициируем данные на CPU. После этого мы должны пойти и скопировать то, что у нас лежит на CPU на GPU память. Просто вызываем функцию cudaMemcpy и копируем из одного массива в другой. И вот происходит вызов нашей Kernel функции, где мы указываем количество блоков, тредов, наши массивы, и после чего копируем итог, результирующий массив. Такая несложная программа.
Все это я запустила на своей 2070 Super и получила ускорение в 400 раз. Стоит обратить внимание – собственно вычисление производилось всего 15 миллисекунд, в то время как копирование данных между GPU и CPU заняло аж в два раза больше времени. Батлнек для GPU – это работа с памятью, копирование памяти, считывание и так далее.
Чтобы уменьшить время копирования, нужно знать, какая вообще бывает память на GPU. Сетка блоков – это наш SM. У каждого блока есть своя shared memory, при этом у каждой нити есть свой регистр. И та, и другая память – очень быстрые. Лучшее, что мы можем сделать – положить наши данные либо в shared memory, либо попробовать уместить их в регистры. Когда мы обращаемся к глобальной или локальной памяти – то, что называется общая память на GPU, – это где-то 400-800 тактов. Чтобы скопировать содержимое локальной памяти на разделяемую память, мы потратим те же 400-800 тактов. Если мы будем множество раз обращаться в разделяемую память, то сэкономим на этом. Также в глобальной памяти можно выделить константную (вы можете обозначить ее спецификатором const или restricted) и текстурную память. В моих задачах это показало некоторое ускорение, но не критическое. Хороший стиль программирования – константное обозначать константной, restricted обозначать restricted.
Первое и самое простое, что мы можем сделать на CUDA – это выделить так называемую pinned memory. Это значит, что мы будем использовать для выделения памяти на хосте не ummalloc, который мы обычно используем в C++, а также вызовем функции из CUDA (cudaHostAlloc или cudaHostMalloc) для выделения памяти на хосте, а не только на GPU. Эта память выделяется непрерывным куском. Обычно ОС отдает нам память кусками – где нашлось, там и выделила. Когда мы начинаем копировать эту память на GPU, мы ходим и ищем эти кусочки и копируем частями. Это довольно долго. Было бы чудом найти непрерывный отрезок памяти, где мы можем взять и выделить свой миллионный вектор. Все, что мы делаем – это просто меняем выделение памяти на cudaHostAlloc. Благодаря этому время копирования данных с 30 миллисекунд уменьшилось до 20 миллисекунд. Вполне ощутимо, учитывая, что наши трудозатраты – поменять одну строчку. Однако, у нас не всегда может найтись такой отрезок памяти. Практически каждая функция в коде всегда возвращает cudaError, там, на какой код ошибка вернулась, все ли у вас хорошо, хватило ли памяти, выделилось ли и так далее. Это относится и к выделению памяти на девайсе, не только на хосте.
Потоки CUDA
Теперь давайте посмотрим, как работать с CUDA стримами. Что такое CUDA-Stream? Все функции на CUDA можно запускать в так называемых CUDA потоках. То, что мы запустим в одном потоке, выполнится последовательно. Но все потоки между собой выполняются параллельно. Если мы не указываем поток, то наши операции по копированию памяти и по вызову ядер будут в одном нулевом потоке по умолчанию и все будут выполняться друг за другом. Также можно использовать и асинхронный вызов. Мы можем разделить данные на несколько потоков и вызывать асинхронно, параллельно, не дожидаясь, пока посчитаются другие данные.
Давайте решим ту же задачу, но мы разобьем наш массив на четыре потока и в четырех разных потоках сделаем все то же самое. Вопрос: будут они быстрее или нет? Ответ: да, будут. Количество потоков ограничено, кажется, числом 32. Если один поток будет достаточно сильно нагружать GPU, у вас не хватит места второму потоку и никакого прироста производительности вы не получите. Чтобы воспользоваться потоками, сначала мы создаем их благодаря cudaStreamCreate. Функции копирования должны быть асинхронными (Async). В функции ядра мы указываем конкретный поток, какому ядру выполняться. Копируем данные обратно, синхронизируемся. С потоками время от времени нужно синхронизироваться. Потом делаем дестрой потоков (cudaStreamDestroy).

Казалось бы, хочется все переписать в один for. Но это не сработает так, как мы хотим – изменится последовательность и исчезнет асинхронность. Какой прирост нам дают стримы? 785х. Копирование данных нам удалось сократить с 30 миллисекунд до 8 миллисекунд.
Таким образом, вот два основных приема, которые от разработчика не требуют много усилий. Первое – это попробовать выделенную память на хосте заменить на pinned memory. И второе – добавить CUDA-стрим. Если ваши данные можно считать параллельно, не дожидаясь, пока посчитались другие данные, воспользуйтесь CUDA стримами.
Перейдем к разделяемой памяти. Это одна из самых быстрых памятей, которые нам доступны. Для демонстрации разделяемой памяти я взяла задачу N тел. У вас есть несколько точек, в нулевой момент времени они как-то рандомно распределены, и на них начинают действовать силы притяжения и отталкивания. Чтобы воспользоваться shared memory, нужно просто добавить спецификатор shared. Если у вас статическая память, то вы добавляете спецификатор shared, а если динамическая, вы должны третьим параметром в Kernel-ядре указать количество нужной вам динамической памяти и функция syncthreads используется для того, чтобы синхронизировать потоки после копирования в разделяемую память и с ней можно было работать.
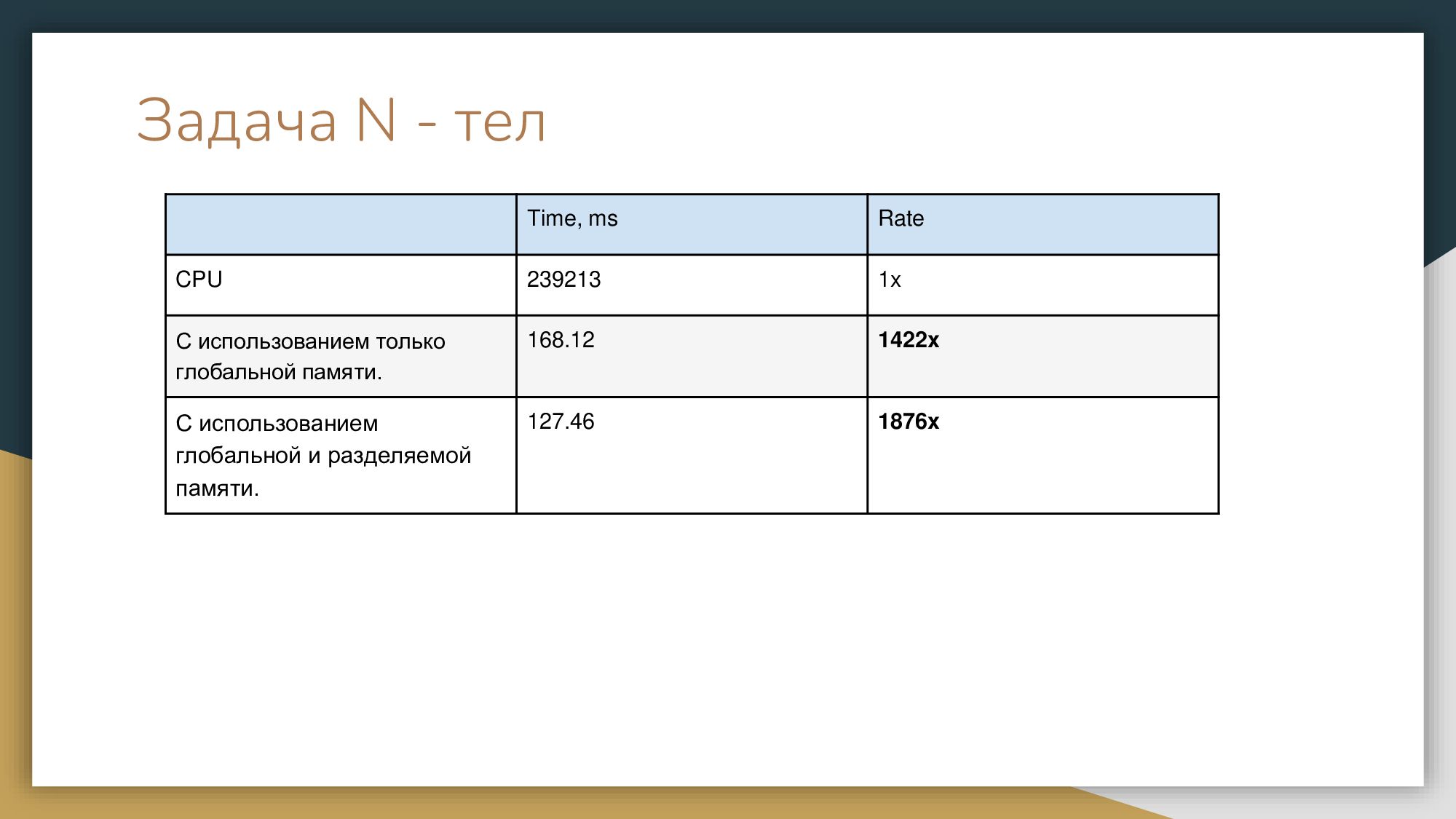
Мы, как обычно, считаем номер нити, указываем два массива, с а также что будем использовать shared memory и источник, откуда копируем. Нужно пойти и планомерно скопировать из глобальной памяти в разделяемую память, после чего синхронизировать. Затем у нас идут расчеты и работа с разделяемой памятью, потом мы синхронизируем и результат, как обычно, копируем на хост. Давайте посмотрим, какой у нас получился профит от этих действий. Как мы видим, не очень большой. Если мы использовали только глобальную память – 168 миллисекунд. С использованием разделяемой памяти мы сэкономили 40 миллисекунд. Довольно неплохо, но уже требуется некоторая мозговая деятельность от разработчика.
Банк-конфликты
Самое неприятное, что у вас может возникнуть – это так называемые банк-конфликты (conflict in memorybanks). Когда нам нужно из глобальной памяти куда-то скопировать, мы копируем некими блоками. Эти блоки называются банки, обычно 4 или 8 байт. Если нам нужно более мелкое слово, 1 байт и так далее, нам все равно нужно пойти и обратиться к 4 или 8 байт, это зависит от архитектуры. В этом случае могут быть конфликты. Допустим, у вас 4-х байтные банки, и есть какой-то массив чаров по одному байту. И в один банк размером 4 байта вы положите 4 чара. Допустим, каждая нить обращается к одному чару. У вас 4 нити обратятся к одному и тому же банку, причем к двум разным ячейкам. Когда они пытаются войти через одну дверь, возникнет конфликт. Этот варп будет ждать другого варпа. То, что раньше производилось параллельно, начнет производиться последовательно. И вы будете терять очень много на ожидании.

Я покажу вам саммари ситуаций, когда происходят конфликты. И я хотела бы это проиллюстрировать на задаче – перемножение матриц. Код здесь большой, там огромный листинг, поэтому я не вижу смысла его приводить. Мы все знаем, как перемножаются матрицы. Что у меня получилось, когда я попробовала перемножить матрицу размером 4000х4000 с разделяемой памятью, не беспокоясь о конфликтах – просто разбила на левые блоки. У меня сильно упала производительность из-за этих конфликтов. Есть разные способы их избежать.
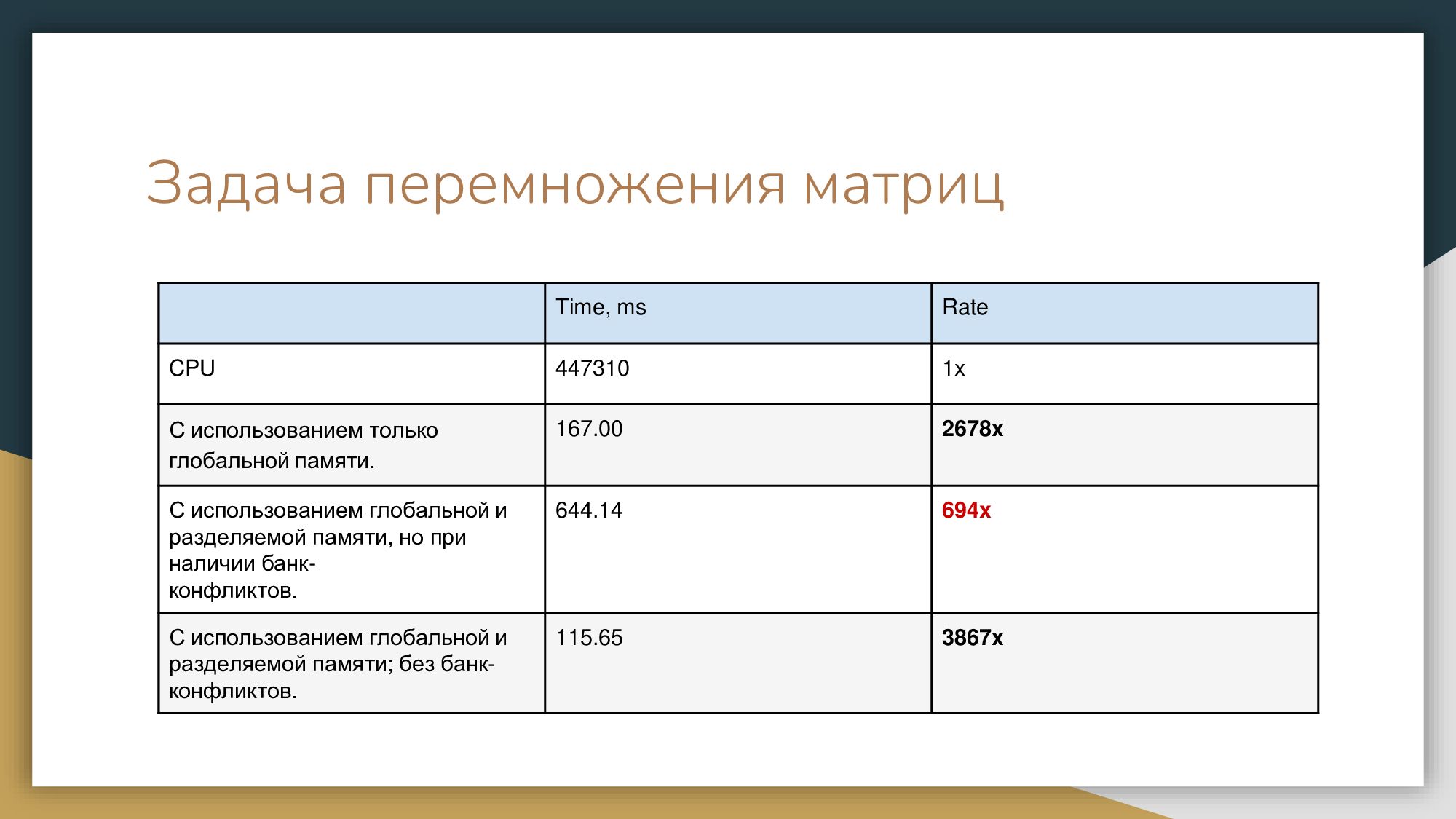
Посмотрите, какой кошмар творится на GPU, если мы неправильно обращаемся с разделяемой памятью и выбираем блоки и слова. С разделяемой памятью нужно быть осторожным. Первое, что вы можете – попробовать поставить слово shared. Если у вас все хорошо - поздравляю! Но так бывает далеко не всегда без дополнительных телодвижений. Банк-конфликты в основном решают тем, что добавляют либо некий stride, либо более объемно бьют на блоки. Когда мы избавились от банк-конфликтов, мы сэкономили где-то около 40 миллисекунд для GPU.
Последний способ, который я бы хотела вам рассказать – это Instruction Level Parallelism. Он дает производительность, когда GPU не нагружено до конца. Вы можете добавить параллелизм еще и на уровне инструкций и тогда получить профит. Мое последнее измерение ускорилось практически в два раза. Матрицы перемножались по 16, по 32 блоков, блочное перемножение по 16, по 32, и я просто уменьшила размер блока и увеличила в два раза количество операций. Я получила прирост просто за счет того, что у GPU стал более нагружен и выполнил все быстрее.

Q&A
Q: Как нормально профилировать на Линукс? Как поймать момент, когда я допустим, слишком много выдал потоков?
A: Command-line. Ты можешь запустить command-line NVidia Profile, он вполне корректно и хорошо отрабатывает на одном приложении. Он рисует тебе CUDA стримы, твои вызовы памяти и ты можешь увидеть своими глазами. Хороший параметр, на который нужно смотреть - это GPU load, нагрузка. Но NVidia Profile содержит очень много информации. Сначала ты проводишь первичный анализ приложения, потом анализируешь что-то, потом еще что-то и так через несколько итераций приходишь к результату, но это занимает некоторое время.


