
Что такое point-based детекторы и как они устроены, о CenterNet и о том, как сделать любую сеть лучше — об этих темах пойдет речь в статье.
Что есть задача детектирования? Это обнаружение на изображении или видео объектов, точнее, прямоугольников вокруг них. В прямоугольнике есть стороны, параллельные оси координат, а также класс, к которому он принадлежит.

Вот пример того, как выглядит детектор одного класса людей на базе CenterNet. Помимо него в мире есть полно детекторов.
Распространённые виды Object detectors:
- YOLO
- SSD
- Faster R-CNN
- RetinaNet
- CenterNet
- EfficientNet
- Cascade R-CNN
Попробуем определить с помощью опроса, какой из них самый лучший. Лидерами среди ответов стали Faster R-CNN и CenterNet.
На мой взгляд, в мире существует 2-3 типа детекторов: single-stage детекторы и их развитие до anchor-based и two-stage версий. Все эти названия из списка — то, насколько инженерная мысль довела людей до конкретных реализаций. Замечу, что некоторые мои высказывания достаточно субъективны и вы можете быть с ними не согласны.
Как устроен YOLO
В 2015 году появился первый популярный детектор YOLO. Я говорю об одной из первоначальных версий статей — если зайти в архив, видно, что через несколько ревизий была изменена идея. Но мне нравится первоначальная версия YOLO.
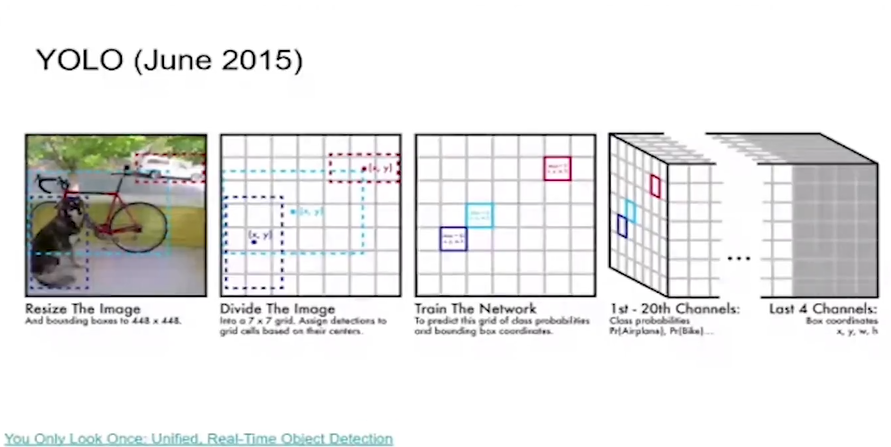
Она работает особым образом. Есть картинка, которая проходит через backbone. Также у нас есть хитмапа 7х7, здесь на этапе тренировки мы помечаем, где находится центр. Находим центр у каждого объекта на картинке, ту самую ячейку помечаем как true positive, — это и есть центр объекта. После того, как мы натренировали детектор, у нас появляется карта, где указана ячейка-центр объекта, и к какому классу объект принадлежит.
Это делается с помощью тензора с 20-ю каналами из тета-сета Pascal. По каждому каналу есть хитмапа 7х7, она говорит нам, что в этом канале располагается объект данного класса. Также есть 4 общие координаты: x, y — уточнение центра, и w, h — ширина с высотой. Это была изначальная идея YOLO, которая скатилась в anchor-based подход.
Как устроен CenterNet
Спустя 4 года после YOLO появляется CenterNet, который работает следующим образом: есть картинка, мы её по умолчанию даунскейлим до определенного размера, сохраняя аспект ratio. Применяем аугментации, бэкбон, и в конце получаем тензор с тремя выходами:

- Хитмапа с центрами объектов. Их всего С по количеству классов.
- Два офсета, уточняющих центр объекта — Δх и Δy, они нужны потому, что уменьшается пространственная размерность. Если входная картинка имела размер w, h, то по умолчанию хитмапа имеет размеры h/4 и w/4. Мы получаем размерность в 4 раза меньше позиций, поэтому центры неточные, нам нужны Δх и Δy, чтобы их уточнить. То есть, сделать сдвиг на 4 пикселя, если требуется. Это не регламентируется в тренировке — сдвиг может быть больше, чем на 4, но это маловероятно.
- Два выхода, определяющих ширину и высоту объекта.
Между первой YOLO и первым CenterNet я не вижу отличий. Если взять Pascal, C = 20, так как классов 20. Получаем те же 24 выхода, как в оригинальной YOLO.
Если взглянуть на идеологию и архитектуру, они одинаковые. Сложилось впечатление, что авторы YOLO не просто так в первой версии сделали что-то вроде CenterNet, а потом, спустя полгода, их статья поменялась и стала содержать в себе анкоры, как это делает SSD. Это говорит о том, что ранее у них был неудачный эксперимент, но с анкорами всё получилось.
Ещё раз повторюсь — YOLO появился в середине 15-го года, в конце 15-го же появился SSD, и все двинулись в сторону анкор-based подхода, в том числе, YOLO9000. Почему идея точь-в-точь как у CenterNet перестала работать или стала работать хуже, чем анкор-бейсд?
Есть варианты:
- Бэкбон, который ориентирован на сегментацию;
- Наибольшее выходное разрешение;
- CenterNet стал полностью сверточным;
- Переход от L2 loss к Focal loss.
Никакая из этих фич не может давать кардинального выигрыша. То, что мы используем полностью сверточную сеть — это лучше: никакие fully connected и detection не нужны, но глобально это не может сильно улучшить сеть.
Modern backbone — сильная вещь. Это не причина, почему YOLO провалилась, ведь мы сравниваем версии с анкорами и без анкоров. Сегментационно-ориентированный бэкбон — вряд ли; большое выходное разрешение — возможно, но и с маленьким это бы тоже работало.
Ещё один ответ — позитивно-негативный сэмплинг. Это как раз специфика анкор-бейсд подхода — для тренировки настроен сэмплинг позитивов и негативов. Hard negative mining — это очень большая головная боль, но в CenterNet’е его нет — он там не нужен. На мой взгляд, причина, почему все не любят анкор-бейсд подход и pos/neg сэмплинг в том, что он сильно усложняет архитектуру и доставляет много проблем.
В качестве резюме можно сказать: две вещи, которые были сделаны неправильно и повели нас по ложному следу — это неиспользование полносверточной сети и неправильный loss для классификаций. Всё остальное вторично: если мы это фиксируем, то и эксперимент получится достаточно валидный.
Нахождение ключевых точек в CenterNet
Никто не мешает сделать anchor-based CenterNet. На первом шаге мы находим ключевые точки на хитмапе, находим максимальные отклики и принимаем эту позицию за центр объекта. Дальше по этим координатам х и y мы переходим в тензор, где выполняется регрессия. Берем оттуда значения x,y смещения для каждой ключевой точки. После этого у нас появляются координаты каждой из ключевой точек и по ним мы находим ближайшие keypoint’ы. Еще один дополнительный шаг рассчитывает смещение для каждой ключевой точки на тепловой карте, чтобы компенсировать падение пространственного разрешения.
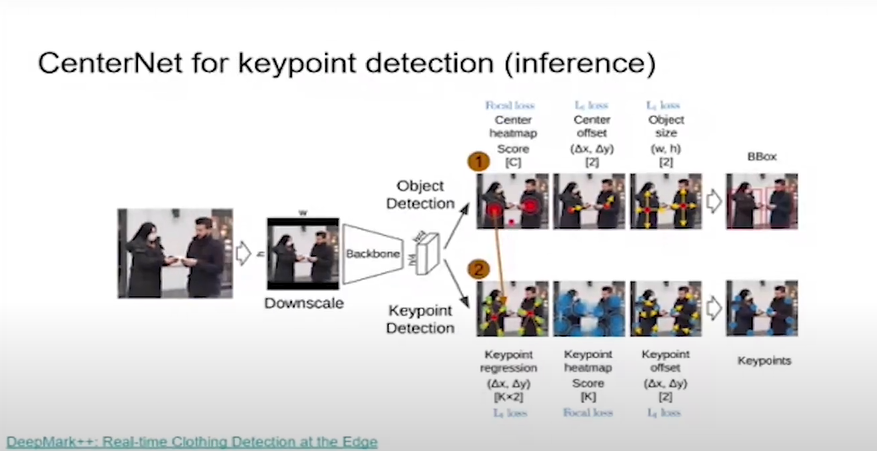
Вот так работает CenterNet для ключевых точек. Аналогично он действует для предсказания трехмерных баундинг боксов и instant сегментации. CenterNet может решать огромное количество задач со своей простой и понятной архитектурой.
Особенности CenterNet
Если вы тренируете CenterNet, уже через 5-10 эпох вы должны получить хорошее качество, как на графике с примером.
На слайде изображен пример детекционной задачки на COCO. Через 5 эпох качество по COCO метрике aMP достигает 26 aMP, в то время как финальная — 42. И если вы запустите инференс через 5 эпох, вы получите адекватный результат. Многие сети anchor-based не могут этим похвастаться. Такая особенность помогает легко идентифицировать ошибку в коде. Если вы не видите такой картины, когда быстро появляется неплохое качество — скорее всего, в коде есть ошибки.
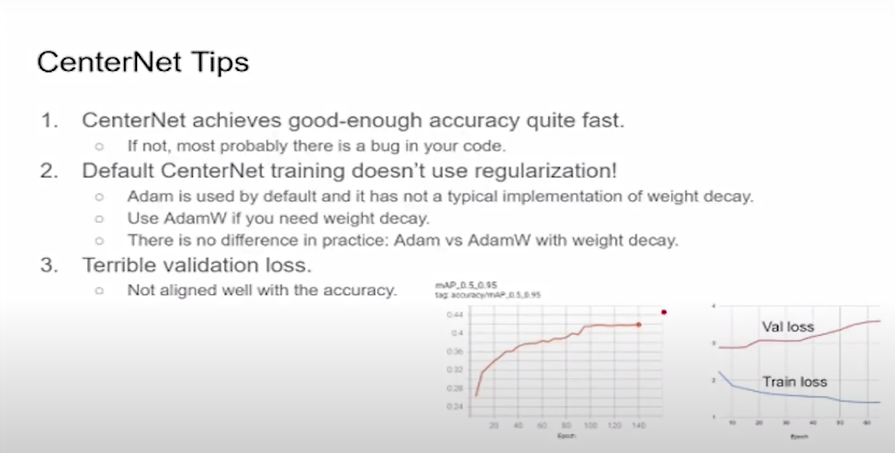
В дефолтной реализации CenterNet нет регуляризации. Сеть тренируется без этого, веса могут улетать куда угодно в бесконечность, сеть может разваливаться — это нормально в такой конфигурации.
Для тренировок используется Adam, и это достаточно странное решение авторов. Тем не менее, в реальной жизни развалить CenterNet тяжело. Это можно сделать: дойти до конфигурации, в которой произойдет взрыв градиента, и в конечном итоге сеть разойдется, — но достичь этого тяжело.
Если говорить про обобщающую способность, для которой мы используем регуляризацию, в частности в weight decay, дефолтные конфигурации достаточно комфортные — проблем с регуляризацией нет.
Eсли вас это беспокоит, рекомендую перейти с Adam на AdamW. Adam нельзя использовать, потому что у него нетипичная реализация weight decay. Это известная проблема, которую фиксит другой оптимизатор AdamW, который есть во всех фреймворках. Вы можете взять AdamW, добавить weight decay, например, 10-3 и жить спокойно с тем, что веса не улетают. Можно подобрать для AdamW такие параметры, как и при обычном адаме, но так будет гораздо спокойнее.
Как сделать CenterNet лучше
Один из ответов в опросе выше — «Надо использовать CenterNet2». Авторы CenterNet не так давно выложили код для двухстадийной версии детектора. По сути, они взяли Cascade R-CNN, прикрутив к нему CenterNet. Прекрасное решение — сейчас они на 2-ом месте на Papers with code.
Если вам нужна жирная двухстадийная архитектура — CenterNet отлично подойдет для RPN-сети, которая делает пропозалы. Есть еще небольшие нюансы организации Cascade R-CNN, но это типичная двухстадийная архитектура.
Сегодня я расскажу про стандартные техники, которые можно встретить в сегментации в детекшене, которые позволяют улучшить качество.

Мы с коллегами занимались этим для решения задачи детектирования ключевых точек. Обратите внимание на первый столбец с показателями, которые мы улучшали — это и была целевая функция. Мы смогли улучшить качество на 2,3 mAP по ключевым точкам всего лишь замедлив инференс на 2,26 миллисекунды на мобильном телефоне на одном потоке. Пост-процессинг здесь не был распараллелен.
Всего лишь на 2 миллисекунды медленнее, но мы получаем выигрыш в целых 2,3 mAP. Если бы нашей целью было оптимизировать баундинг-боксы, то похожие техники тоже можно было бы использовать. Что же это за техники?
Center rescoring
Так как мы детектировали ключевые точки, для каждого объекта у нас было несколько скоров. Первый скор — это скор от прямоугольника. По хитмапе в центре объекта у нас был скор 0,31 для одежды с короткими рукавами, 0,29 — для одежды с короткими рукавами.

У key-поинтов тоже есть скоры, потому что они тоже расположены на тепловых картах. Мы можем собрать все точки и получить среднее значение. На данной картинке видно, что сеть сделала ошибку для класса, определив её как одежду с короткими рукавами. Так получилось, потому что неудачно расположены ключевые точки. При этом, если key-point’ы расположены удачно, и класс правильный, то всё хорошо определяется.
Если сможем использовать эти два значения с помощью линейной комбинации, то получим лучший результат. Если сеть выдает несколько скоров для одного и того же объекта, давайте их использовать. При этом, параметр ⍺ — это гиперпараметр, немного позже расскажу, как его получить.
Heatmap rescoring с гауссовой функцией
Другой известный подход — использование размытия по карте. В данном случае сеть стала работать на какие-то копейки, но быстрее. С чем же это связано? Почему мы добавили еще одну операцию, но процесс стал быстрее? Если что, в total time учитывается время постпроцессинга.
Ответ такой: уменьшилось количество вариантов после threshold’а, и у top-k получается меньшее значение.

За счет размытия мы убираем выбросы, в топ-к уменьшается количество кандидатов и построцессинг становится быстрее. Эта простая операция интегрируется и прекрасно работает в любом CenterNet и на любой хитмапе. У нас были разные сигмы, но они зависят от задач: одна подходит для центров, другая — для хитмап по ключевым точкам.
Уточнение локации
Здесь также используется идея Ensemble. Сеть предсказывает CenterNet две локации для ключевых точек: исходную — грубую, полученную с помощью регрессии, и финальную, полученную после уточнения. Нам никто не мешает с помощью линейной комбинации найти оптимальное решение. Это добавляет целый 1 mAP с минимальными затратами.

Объяснение этому следующее: грубая оценка и смещение могут оказаться лучше, чем уточненное по хитмапе. Мы такое наблюдали, и линейная комбинация исправляет ситуацию, когда грубая оценка была лучше.
Рескоринг ключевых точек
Последняя техника связана с особенностью этапа декодирования в CenterNet. Возьмем хитмапу для ключевой точки, сделаем проекцию на какую-нибудь ось, поставим значение, где было срегрессировано примерное положение ключевой точки и отметим все остальные отклики на хитмапе.

Достаточно типичная ситуация, когда есть вот такие выбросы, которые больше дефолтного порога (в CenterNet это 0,1).
Алгоритм декодирования следующий: мы находим ближайшую в некотором радиусе ключевую точку на хитмапе, и она была бы выбрана как правильная, хотя очевидно, что нужно брать другую. Можно добавить перевзвешивание с помощью гауссова ядра, тогда при правильном выборе 𝛔 ключевые точки имеют большой скор, и мы будем выбирать их вместо тех, что были выбросами.
Также нейронная сеть может быть проинтегрирована как отдельный слой. В этом случае мы не будет писать код на осях, это будет ещё один слой в нейронной сети.
Выбор гиперпараметров
Эти техники работают с фиксированными нейросетями, которые не надо перетренировывать. Вам нужно выбрать каждый из параметров каким-то образом, например, сделать перебор. Есть известное решение в виде рэндом-сёрча. В данном примере я покажу, что будет, если мы запустим грид-серч, поиск в нейронетной сетке.

Здесь показаны 4 параметра: сверху параметры из первой техники от 0,7, 0,75 и так далее. По оси Y показаны параметры по технике 3 таким же образом. Каждый квадрат внутри соответствует 𝛔 для техники 2. Напомню, 𝛔 — это значение размытия для центров и хитмапа ключевых точек. Ось х — центр ключевой точки или центр объекта, а по оси y — ключевые точки.
Если мы хотим найти глобальный максимум, он помечен белым крестиком. Остальные крестики были получены на разных дата-сетах. Если вы запустите грид-серч, независимый для каждого параметра, нам не нужно делать декартово произведение. Если вы выберете неплохой дата-сет, то все точки будут близки к глобальному оптимуму.
Это понятно, потому что на каждом квадратике, на каждой из хитмап видно, что качество представляет собой унимодальную функцию с одним максимумом, и этот максимум находится всегда в одной и той же точке. Если для каждого из параметров вы найдете оптимальную точку Z, то получите некоторые значения, близкие к глобальному оптимуму, полный перебор делать не надо.
Есть ещё 3-я особенность — все эти параметры могут быть встроены прямо в нейросеть, и в ней же обучаться. Не нужно их выбирать, нейросеть сделает это сама. Никаких ограничений нет, вы можете сделать это самостоятельно безподборов и параметров — сеть сделает всё сама и всё будет замечательно.
Резюме
Вот вещи, которые я в итоге бы хотел донести:
- CenterNet я вижу как переосмысление того, что было предложено в YOLO. Идеологически они похожи, но интерпретация в CN другая. За счет этого мы можем решать большее количество задач в простом режиме без танцев с бубном с анкорами. Анкоры — это тяжело.
- У CN есть свои особенности: отсутствие weight decay по дефолту. Это не проблема, но стоит иметь в виду. Проще всего сразу перейти на AdamW.
- Есть куча известных техник, позволяющих улучшить нейросеть с минимальными временными затратами и скорости инференса, но с существенным выигрышем. Для продуктовой разработки мы использовали эти решения, и они действительно добавляют качество.
Q&A
Q: Мнение, что CN базировались на YOLO — не авторское?
А: Нет, авторы так не считают. Та интерпретация, которую я назвал, субъективна. Это моё личное мнение на основании того, что я давно изучаю детекционные сети. Авторы CenterNet ни в коем случае не считают свою работу развитием YOLO или чего-либо, они считают его уникальным решением, и я с ними согласен.
СN подарил миру новую интерпретацию того, как могут работать детекционные сети. Проблема YOLO в том, что люди не добили эту идею. Спустя полгода они ушли от изначальной идеи центрнет к anchor-based подходу, как это было в SSD. Это можно отследить по ревизиям статьи. На долгие годы, до 19-20-го, люди жили на anchor-based подходе. Point-based тоже существовали, но были не так популярны.
Q: Какие какие истоки у CenterNet? Неужели они придумали регрессировать шифты?
A: Шифты регрессировать придумали не они. Если открыть оригинальную YOLO, мы увидим, куда попал центр объекта. Из этого центра мы регрессируем смещение x, y и прямую предсказываем w, h — это первая версия YOLO. Говорить, что это изобрел CenterNet у меня не поворачивается язык, потому что YOLO выглядела абсолютно так.
Проблемы YOLO, те места, где споткнулись, возможно даже ошибки в коде они довели до конца. Но сама идея регрессировать смещения и w, h абсолютно не нова. У них получилось написать рабочий код, который сейчас очень популярен и все им пользуются.
Q: Какие библиотеки используете для обучения CenterNet?
A: Сейчас я использую PyTorch 1.7 и оригинальный CN со своими модификациями. В оригинальной версии CenterNet некоторые вещи мне не нравятся. То, чем мы занимаемся в Camerton, мы делаем в CenterNet, и мы его переписали так, как нам удобно.
Q: Какое ПО используете для разметки данных по ключевым точкам?
A: На самом деле, я не занимаюсь этим сейчас. Раньше мы пользовались CVAT для решения этих задач. Для ключевых точек мы не занимались разметкой данных даже когда делали продуктовую часть. Разметкой занималась другая команда, поэтому мне трудно прокомментировать, какой тул для разметки они использовали. Внутри команды мы всегда использовали CVAT. Я считаю, это один из лучших инструментов.
Q: В конце доклада было сказано, что можно занести параметры сглаживания прямо в сеть, попробовать это обучить, и должно стать лучше. При этом в самом начале было сказано, что существует рассинхрон между лоссом и финальной метрикой. Нет ли ощущения, что если добавить параметры и попробовать их обучить, то станет хуже? Кажется, что таким тюнингом вы выправляете рассинхрон лосса и целевой функции.
A: Хороший вопрос. Утверждение, что мы выправляем лосс мне кажется неверной, потому что с самим лоссом проблем нет. Мы можем получить одно и то же мАP с разными значениями loss. Условно говоря, нет большой разницы с фолс-позитивами, есть у них скор 0,85 или 0,88. Есть определенная разница, но можно привести пример, когда этой разницы не будет.
По материалам открытого семинара Алексея Сиднева «Point-based object/keypoint detector CenterNet: Tips and Tricks», который прошел в Xperience.AI.