
Поговорим про применение трансформеров в компьютерном зрении: что такое трансформеры и откуда они пришли, рассмотрим основной механизм внимания в основе данного типа моделей.

Все статьи, о которых мы говорим, предлагают некоторый бэкбон на основе трансформера без использования сверток. Применение трансформеров и механизмов soft attention в компьютерном зрении было и до этого в разных моделях, но скорее в качестве вспомогательного механизма. По моему мнению, за последние полгода произошел большой прогресс в использовании трансформеров для задач компьютерного зрения.

Одна из важных статей на «Papers with Code» от 2017 года — «Attention is All You Need». Она совершила революцию в области обработки естественных языков и предложила новую модель для решения задач машинного перевода. После этого было предложено ещё несколько новых моделей на базе трансформера, которые справлялись с задачей с лучшим качеством.

Можно выделить две главные ветви развития моделей:
- GPT, которая училась решать задачу языкового моделирования и предсказания следующего токена. Токен может быть словом, символом, другой языковой единицей или кодировкой. Когда модель вышла в 2018 году, она была популярна только в узких кругах специалистов, которые занимались задачами, связанными с NLP. В прошлом году вышла уже третья версия, и она сделала много шума — даже люди, никак не связанные с Deep Learning, NLP или Control Vision слышали об этих моделях, так как она значительно улучшает качество генерации текста.
- BERT, который предложил новый подход к обработке естественного языка. Смысл в том, чтобы выучить одну большую модель, и на основе полученных эмбеддингов мы можем напрямую решать задачи, либо ещё немного дообучить(зафайнтюнить) модель под конкретные таски, например, под текстовую классификацию или recognition.
Начиная с прошлого года, трансформеры начали плавно перетекать в Computer Vision, из-за чего произошел настоящий взрыв статей.
Архитектура трансформера
Изначально предложенная архитектура строилась по принципу энкодера-декодера, и решала задачи машинного перевода. Грубо говоря, есть часть, которая кодирует наш текст на вход — энкодер, а есть та, которая потом декодирует в другой текст на другом языке — декодер.

Нас интересует только левая часть слайда под названием энкодер, потому что он используется и в GPT, и в BERTA, в моделях, о которых мы будем говорить в дальнейшем. Декодер в некоторых задачах компьютерного зрения тоже используют, но энкодер все-таки чаще. Тем более, что они похожи — за исключением нескольких различий.

Устроена она довольно просто: есть базовый блок, из которого складывается энкодер, то есть n повторяющихся базовых блоков. Внутри базового блока есть несколько слоев, самые важные из которых — Self-Attention, Layer normalization, skip connections и dense layer.
Механизм Self-Attention
Идея следующая: у нас есть некий токен, и мы хотим оценить важность других токенов относительно него. Эту операцию мы будем проводить со всеми имеющимися токенами.

Так мы посмотрим, как каждый токен влияет на другой. Сам механизм, который мы назвали self-attention, имеет несколько модификаций — на слайде находится классическая версия. Он основан на scaled dot-product attention и устроен из некоторого перемножения матриц. У нас есть input матрица Х на входе — это матрица эмбеддингов, также у нас есть n — количество токенов и размерность d — размер эмбеддингов, либо их еще называют model size. Здесь же мы видим три матрицы весов, которые обучаем, c тремя разными значениями query key value.
Все эти матрицы одинаковы с точки зрения размерности, но имеют несколько разный смысл. Перемножив эти матрицы на матрицу на входе, мы получим три других матрицы — Q, K, V. После того, как мы нашли другие матрицы наших изначальных эмбеддингов, мы проводим следующую операцию: умножаем матрицу Q на транспонированную матрицу К, нормализуем, считаем софтмакс по строке и умножаем на последнюю матрицу V.
Таким образом, мы взвешиваем важность токенов в матрице V, при этом посчитав self-attention относительно друг друга. Если посмотреть на размерность матрицы после перемножения Q на К, она будет n-ная — получается, что мы смотрим на все токены относительно всех других.
Эта операция синтетически квадратична по сложности, это зависит от размера токенов или параметра n. Чтобы лучше проиллюстрировать, покажу пример. Он более детальный, потому что мы умножаем здесь не матрицы, а векторы.

Мы берем два токена и их эмбеддинги, три матрицы матрицы весов Query-Key-Value и перемножаем наш вектор на три матрицы. После того, как мы получили три вектора, мы можем посчитать attention. В данном случае мы получаем dot-product, то есть скалярное произведение. Мы его нормируем, считаем софт макс, умножаем на вектор Value и после этого будем суммировать по всем этим значениям относительно первого токена. Ту же операцию мы проделываем со вторым токеном, и получаем уже другое значение.
Multi-head attention
Self-attention сам по себе не применяют, для него придумана надстройка, которую называют Multi-head attention. Её концепция в том, чтобы использовать не одну матрицу весов для каждого Query-Key-Value, а целый набор разных матриц, которые будут проецировать наши эмбеддинги в некоторое пространство в размерности меньше первоначальной. Там мы будем применять self-attention и все полученные после операций значения мы сконкатенируем.

Чтобы вернуться в изначальную размерность мы ещё умножим на некоторую матрицу Wo — это линейная проекция, которая поможет вернуть нужную нам размерность. Концептуально это звучит сложно, и непонятно, почему это должно работать, но люди в процессе пытались включить интуицию.

Рассмотрим пример обработки естественных языков. Если посмотреть на отдельные токены и self-attention в разных головах, то они смотрят на разные токены. В одной голове относительно токена «it» будет токен «the animal». То есть имя то же, но в другом виде. Во второй голове мы будем уже смотреть на глагол относительно токена. Теоретически интуиция работает не всегда: если смотреть на более свежие слои и другие головы, уже не понятно, что учится, но на практике интуиция работает.
После того, как мы вспомнили, что такое трансформер и self-attention, вопрос: зачем это применять в компьютерном зрении, если есть сверточные сетки, которые себя зарекомендовали? Вроде они и сами отлично работают последние десятилетия, достигают действительно хороших результатов в задачах.

Если подумать, в сверточных нейросетях заложены априорные знания о том, как устроены картинки. Это одна из причин, почему они так хорошо действуют. Есть так называемые inductive bias или inductive priors, которые позволяют нам уменьшать количество данных, необходимых для обучения сетей. Им немного проще решать задачу, чем полносвязным сетям либо трансформеру, который не обладает такими знаниями.
Примером такого явления служит понятие локальности. Оно заключается в том, что пиксели, которые находятся рядом, больше скоррелированы между собой. Может произойти так, что у нас происходит резкий скачок в значениях пикселей. Это говорит о том, что есть некоторая локальность объекта, и если мы нашли его признаки, нужно смотреть в окрестностях.
Вторая причина — это translation variants. Если мы меняем положение нашего объекта на картинке, свертка так или иначе до него дойдёт, что совсем не очевидно с полносвязными слоями. Если мы применяем инпут, для сетей это будет уже совсем другой инпут и другой результат.
Другие вспомогательные идеи, — то, как шарятся веса. С одной операции в рамках одного слоя мы идем с одним набором весов и их шарим. Если есть схожие локальные паттерны, мы их уже будем находить, применяя меньшее количество ресурсов. Так получается, потому что часть весов уже есть, и не нужно их хранить для каждого конкретного случая.
Последний вариант — это некоторая иерархичность системы. Мы знаем, что на ранних слоях есть более конкретные признаки объекта, они более низкоуровневые. Чем дальше, тем более абстрактными получаются признаки самого объекта.
Vision Transformers (ViT)
Всех этих особенностей в трансформере нет. Соответственно, чтобы он хорошо работал, нужно всё это выучить, а чтобы выучить, нужно много данных. Это одна из причин почему разработчики так долго к этому шли.

Вторая причина — это как подавать на вход картинку для такой модели. Модели и статьи, которые были до этого, предлагали собрать некоторое внутреннее представление с помощью сверточных нейросетей, и у нас уже уменьшится разрешение до совсем крохотных размеров. Все, что выучили, уже будем подавать на вход.
Авторы статьи предложили вообще не использовать свертки, а давать сырую картинку. Идея достаточно простая, возможно раньше не было раньше вычислительных мощностей и количества данных, чтобы довести все до ума.
Первая идея, которая приходит в голову, — выкинуть картинку в один огромный вектор, где каждый пиксель — компонент вектора. Но это не очень хорошая мысль потому что размерность вектора n, которая квадратична, будет слишком огромной. Авторы статьи предложили нарезать картинку на некоторое количество небольших кусков. Оригинал статьи называется «An Image is Worth 16x16 Words», потому что в ней было предложено использовать куски 16х16 вместо целой картинки.
Это гиперпараметр, от которого напрямую зависит количество токенов. На слайде это параметр обозначен как P (Patch size), мы делим на него, и получаем обратную пропорциональную зависимость. Изображение нарезаем последовательно на несколько патчей, и с помощью некой обучаемой матрицы эмбеддингов мы проецируем нужную нам размерность. Также есть набор токенов с заданным размером эмбеддингов, и мы можем подавать его на вход трансформерам.
Ещё одна небольшая деталь — это positional encoding. Трансформер сам по себе ничего не знает про расположение пикселей в пространстве, для него это просто множество токенов. А для того, чтобы выстроить токены в последовательность, используют positional encoding.
Авторы статей пробовали более сложные способы кодирования. В 2D коде есть два компонента для X и для Y, потому что это картинка, а не последовательность. По сути, достаточно было выстраивать последовательность из патчей. Авторы тренируют сеть такими патчами, которые мы прогоняем через некоторое количество энкодер-блоков.
Они используют в сверточных сетях тот же принцип, что и мы: берут какое-то последнее представление, переводят фичмапу (feature map) в вектор. Этот вектор прогоняем через полносвязный слой и напрямую предсказываем через софтмакс вероятность классов.
То есть они используют специальный токен, который отвечает за принадлежность к классу. Это обучаемый эмбеддинг для классификации на последнем слое, остальные признаки не используются. Не знаю, почему не попробовали делать, как принято, это скорее рудимент среди подходов, похожий на BERT, но это работает. Удивительно, что они вообще не меняли модель, и оставили BERT в оригинальном виде. В таблице в самом низу есть ViT-base. По всем гиперпараметрам видно, что это тот же BERT.

На самом деле есть подвох: для того, чтобы способ подействовал, им пришлось обучать сеть на огромном количестве данных, что является немного читом.
Обычно мы используем какой-то нишевой датасет и на нем же измеряем качество, либо обучаемся, на чем-то файнтюнимся и решаем конкретные задачи. Здесь, чтобы работать с классификацией на ImageNet, им пришлось обучаться на датасете размерностью 300 млн картинок. Это немного странное решение от Google связано с тем, что необходимо огромное количество данных — у трансформеров нет знания картинок, им нужно показать множество примеров.
Соответственно, возникает вопрос о практичности и о том, можно ли это использовать. На слайде справа мы видим некоторые зависимости от количества данных. Если брать чистый ImageNet и учить только на нем, то этот способ будет менее эффективным, чем классический resnet.
В классическом ImageNet порядка 1 млн картинок и 1 тыс классов. Можно взять ImageNet побольше: например, в ImageNet 21K около 10–12 млн картинок и 21 тыс классов; в последнем проприетарном датасете от Google уже сотни миллионов и 18 тыс классов. С ростом количества данных, ImageNet линейно растет, но если использовать свертки, то можно получить такие же результаты на некоторых моделях с большим количеством параграфов.
Другие интересные свойства ViT
Есть несколько интересных моментов, которые я выделил:
- На первых слоях тоже выучивается представление о базовых фильтрах, которые люди применяли еще в эру классического компьютерного зрения. То же самое могут выучить и сверточные сети. Модели в состоянии выучить иерархию, при этом не имея изначально заложенной информации.
- Существует некоторый аналог receptive field — среднее расстояние, на которое смотрит attention. По оси х — это количество слоев, по оси y — среднее расстояние внимания в пикселях. Мы видим, что чем глубже слои, тем attention более глобальный. Это тоже коррелирует с нашим знанием из сверточных нейросетей, что при увеличении количества слоев receptive field увеличивается.

Что стоит отметить: на самых ранних слоях есть отдельные головы, которые смотрят на глобальную информацию. Получается, что рост рецептив филда не линейный, как в обычных свертках, а более неочевидный.
Data efficient image Transformers
У Facebook есть решение, у которого не было столько TPU, как у Google. Это надстройка к той же модели, но они решали проблему отсутствия знаний с помощью их дистилляции. С ним используют обученную сверточную сеть, помогающую с классификацией, как дополнительный сигнал для выучивания этого bias. То, что она учит напрямую — довольно спорно, но с ней понадобится гораздо меньше данных. Она обучает только на ImageNet без проприетарного датасета с лучшим результатом.

Есть один пункт, который я не добавил: Facebook используют более разнообразную аугментацию, то есть они решают нехватку данных не только с помощью дистилляции, но и с более качественными аугментациями.
Вернемся к дистилляции. Это подходящий метод получения маленьких сетей из больших, что дает преимущество в производительности. Это не основной, а вспомогательный метод улучшения качества. Авторы предложили использовать distillation token — ещё один токен, как тот, что мы использовали для предсказания классов, — он также обучается совместно с эмбеддингами из патчей-картинок.
После прогона через все слои в энкодере у нас появился результат, который мы используем для предсказания функций потерь и подсчета градиента.
Типы дистилляции
Давайте рассмотрим следующий слайд с формулами.
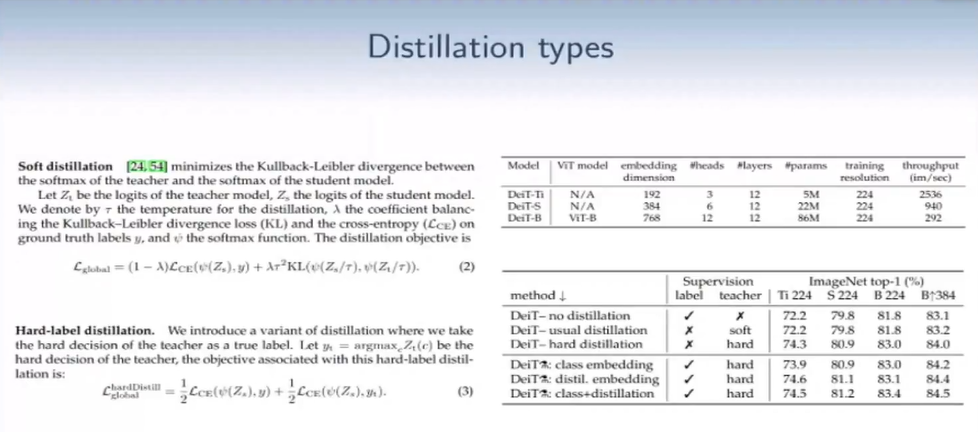
- Soft distillation — классический подход, который предлагали в нескольких статьях. Есть две модели, Teacher и Student. Teacher — большая сверточная сеть, student — vision transformer. Мы применим предсказание с модели Teacher для улучшения качества предсказания Student. Есть такая формула из двух частей: слева кросс-энтропия для классификации, С — это софтмакс. С помощью логитов после выхода модели Student мы применяем софт-макс и считаем кросс-энтропию. Здесь же мы видим правую часть, где считается конвергенция, которая считается способом измерить схожесть распределений. Если распределения похожи, то значения дивергенции небольшие, если разные — то большие. Есть несколько гиперпараметров, которые они используют: первый — λ, способ взвесить два лосса, и 𝑡 — температура — вспомогательный гиперпараметр для сглаживания выходов после софтмакса. Это один подход, с которым можно посчитать лосс и обучаться с ним.
- Авторы говорят, что лучше работает второй подход, который концептуально попроще. В нем две части — одна про классификацию токена, вторая — про дистилляцию. Но вместо непрерывных значений есть конкретное значение выхода Teacher: мы просто берем argmax по логитам и значение, потом с одинаковым весом мы это учим. Лучший результат выходит, когда мы используем привычную классификацию с помощью класс токена и дистилляции. Модель способна выучить из сверточной сети априорные знания, их докидывает дистилляция. Авторы попробовали в роли Teacher не только большую сверточную сеть, но и уже обученный трансформер. Выяснили, что первый вариант работает лучше, чем второй, потому что он быстрее и требует намного меньше информации — примерно 8 TPU за пару дней.
Плюс трансформеров в том, что они очень легко скейлятся, и не нужно ничего придумывать, чтобы получить большие жирные модели, все заводится из коробки. Эта статья выглядит более прикладной. Сомневаюсь, что способ подействует лучше сверточных сетей, если вы возьмете предобученную модельку на ImageNet и пару тысяч классов, размеченных под конкретную задачу.
SWIN Transformer
В первой статье авторы используют дистилляцию, но работают с аугментациями из второй. В статье от Microsoft авторы замечают, что когда мы используем ViT, мы подаем на вход фичмапы одинакового размера. С каждым следующим слоем уменьшается разрешение и увеличивается число каналов. В классическом ViT такого нет: если мы будем увеличивать число токенов, которые мы будем последовательно уменьшать, и наращивать число каналов, то мы очень сильно проиграем по вычислительной сложности, так как она зависит квадратично. Однако выучить некие иерархические принципы тоже хочется, и авторы предложили несколько идей.

Первая идея похожа на то, к чему мы привыкли в свертках. У нас есть разрешение, которое называют стадиями, и с каждым слоем оно уменьшается с некоторой периодичностью. Здесь заложено три основных механизма: первый — patch merging. Это значит, что на первых слоях больше токенов, и мы их мерджим в токены большего размера и получаем локальные окна. На выходе будeт токены, которые связаны друг с другом, как это было в ViT.

Авторы разбивают энкодер-блок на два куска: на вход идут локальные окна, а на втором слое есть операции, которые называются switch transform, и они эти окна преобразуют.

На первом этапе у нас есть совсем локальные окошки, где attention смотрит только на них, и мы не видим все, что за пределами окон. Красные квадраты — это локальные окна, внутри которых мы находимся, и attention находится внутри каждого такого окна. Можно все оставить в таком виде, прогонять и уменьшать разрешение, постепенно увеличивая с помощью мерджинга кусков. Тогда получается, что часть окон будет никак не связана с другими.
Чтобы self-attention был между разными окнами, предлагают такую shift-операцию, которая разбивает окна на сегменты разного размера, прямоугольники и квадраты. Информация из self-attention будет перетекать между этими окнами. Чтобы получить линейность в зависимости от количества токенов, мы сделаем, чтобы между окнами было взаимодействие, и будем уменьшать количество вот этих красных квадратов с помощью мерджинга.
Непонятно почему, но увеличение происходит именно на третьей фазе, на всех предыдущих по 2 блока. В базовом варианте используют 6, 12 и 18 таких блоков с одним и тем же разрешением.
Результаты ImageNet
На предпоследнем слайде не удержался и вставил табличку, хотя все эти цифры не хотелось обсуждать, ведь каждый автор статьи хочет показать их в красивом свете. Но в этой таблице есть все три архитектуры и некоторое соотношение с привычными сверточными сетями типа Fishnet. Есть высокие результаты, но количество параметров и FLOP’ов нечеловеческое и непонятно, как это использовать.

Но если посмотреть на результаты не такого большого размера, то они уже сопоставимы со свертками, пусть и чуть хуже. Сама архитектура остается практически неизменной в классическом виде DeiT. Если улучшать и придумывать хорошие идеи, со временем оно будет работать лучше для некоторых задач, чем свертки. Но пока об этом невозможно говорить, потому что сети переезжают на трансформеры.
Если посмотреть на статьи, которые выходят, их можно разделить на два основных типа:
- Максимально общие, по сути бэкбоуны;
- Те, которые решают конкретные задачи, например, трекинга, action recognition.
Мне кажется, если для решения задач использовать трансформеры не всырую, а настраивать, то это может дать хорошие результаты в будущем. Это подойдет для мультимодальных кейсов, когда, например, есть видео со звуком, а для звуков тоже используют трансформеры.
Видео с разными модальностями — тип данных, который хорошо ложится на эти модели. Возможно, механизм attention, который позволяет глобально смотреть между фреймами, как раз отслеживает и позволяет делать ReID.
Полезные ссылки
- TransGAN explanation от Yannic Kilcher — интересная, но максимально непрактичная статья. Результаты, которые там описаны, выглядят как привет из 2016-го года. То, что получается в других моделях вроде StyleGAN2 это, конечно, ни в какое сравнение не идет. Они используют некоторые трюки: например, берут scheduler, увеличивают с ним receptive field по времени и изначально не дают селф-этеншену смотреть на все токены одновременно. Если интересно, можно посмотреть видео Yannic Kilcher. Отличный канал, где он дает рецензии на свежие статьи.
- Vision Transformers implementation от Phil Wang. Здесь видно, что автор интересуется происходящим, так как его количество контрибьюшнов поражает. Здесь репозиторий чисто про вижн трансформеры, где он сделал несколько реализаций базового ViT и еще кучу других статей. Довольно неплохо устроено, если мы хотим сделать дистиллейшн: указываем Teacher и Student, с оберткой в виде софт дистиллейшн, указываем дополнительные гиперпараметры, потом уже можем учить.
- PyTorch Vision models от Ross Wightman.