
PyTorch Lightning – это обертка PyTorch, которая призвана сделать нашу жизнь проще, а также у нее есть несколько интересных фич, о которых еще пойдет речь.
Установить его несложно: сперва нужно установить Torch, потом мы ставим под него Lightning. У нас PyTorch Lightning совместим с версией Torch 1.1 - 1.5.
Что такое PyTorch Lightning?
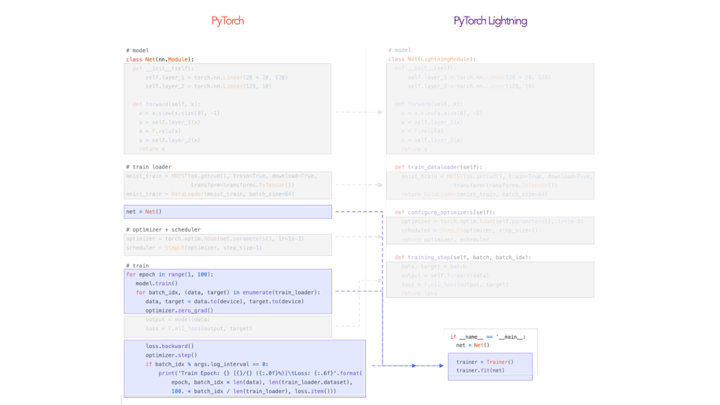
Это такой фреймворк, который существует над PyTorch, и помогает структурировать обычный код Torch, отделив так называемый scientific код от инженерного. Что имеется в виду: инженерный код – это все, что относится, предположим, к train loop, считыванию данных, логированию и так далее. А scientific относится непосредственно к оптимизации, сеткам и все в таком духе. Сами авторы Lightning утверждают, что это не совсем фреймворк, а больше обертка со стайлгайдом. Легче всего посмотреть на примере: он взят со странички Lightning. Пробежимся по обычному PyTorch. У нас есть обычная сетка, в ней есть init и forward; потом мы детализируем дата-сет и data loader, делаем optimizer и scheduler, затем у нас начинается кусочек с train loop. Там высчитывается loss, batch, epoch и прочее. В конце еще и логирование есть.

В чем прелесть Lightning? Теперь у нас есть один-единственный класс, который наследуется от Lightning-модуля, и если раньше это был просто модуль сетки, то теперь он будет находиться в одном классе. Также без изменений переходит сеточка, init, forward и кусочек с data loader. У нас есть train data loader, значит Lightning рассчитывает на то, что мы ему в качестве return будем выдавать сам data loader. Есть кусочек про optimizer и также scheduler. В return предполагается, что мы через запятую эти кусочки перечислим, на первом месте optimizer, на втором scheduler. Также у нас есть training step – это аналог одной итерации их тренировки, где показано, как это вообще нужно делать, то есть, пропускать через key loss. И на базе Lightning нам передается изначально batch и индекс. В нем мы учитываем наши данные, делаем forward сетки и рассчитываем loss. В training step обязательно нужно делать return такого dictionary, в котором под ключиком loss у нас лежит значение нашего loss.
Это все касалось scientific части кода, теперь перейдем к инженерной части, в частности, к train loop. Lightning полностью избавляет нас от использования train loop, с помощью того, что у нас объявляется trainer. fit. Это и есть аналог train loop; в нем можно задавать различные параметры, по типу количества epoch, которые нужно тренировать и так далее.
Дальше я буду основываться уже не на этом маленьком проекте, а на своей курсовой работе, куда Lightning лег просто идеально, потому что у меня получилось написать полностью рабочий пайплайн и хватило двух часов, чтобы первая тренировка полностью запустилась.
Начнем с дата-сета (все функции, о которых я сейчас буду говорить, относятся к сlass от Lightning-модуля). У нас есть какие-то аугументации, которые мы хотим использовать для training, для validation, и мы хотим это сохранить, а Lightning предполагает, что дата-сет мы будем хранить в train, то есть в его местном поле trainset и valset.

Теперь, чтобы сделать из этого data loader, мы объявляем train data loader и обычный data loader Torch – и его возвращаем. То же самое делаем для валидации, единственное отличие в том, что здесь мы подаем тренировочный сет, а в другом – валидационный.
В конфиге optimizer идея одна и та же: у нас есть optimizer, мы объявляем его; потом объявляем scheduler и возвращаем. Если вы хотите использовать два optimizer и несколько scheduler, то вы пишете optimizer 1, optimizer 2 в первом листе, а потом задаете наличие scheduler. Помните, что порядок должен сохраняться: в одном листе идут все optimizer, в другом – все scheduler.
В training step (как я говорил, это то же самое, что итерация) у нас есть batch, есть его индекс, в моем случае, этот кусочек отвечает за форвард; рассчитываем loss, высчитываем высшую метрику. Также у нас есть внутренний логгер в Lightning. Если мы хотим каким-то образом модифицировать эту штуку, то можно объявить какую-то переменную, – в моем случае это progressbar, – и говорим, что мы хотим ее записать. Я хочу, чтобы в моем логгере высвечивалась accuracy. И мы говорим, чтобы в конце, под ключиком progress bar, у нас выдавалось все, что мы в нем хранили. Теперь, после того как мы передали в progressbar еще дополнительную переменную, у нас в нем будет высвечиваться accuracy – двоеточие и число от нуля до единицы. В progressbar можно запихнуть что угодно, дефолт же пишет значение только training lost и валидацию. Тут на картинке есть training step, а validation я не стал указывать, потому что они абсолютно идентичны. И там и там я считаю метрику, loss, единственное отличие – обязательно нужно в качестве параметра в return в dictionary возвращать loss как значение, потому что ему еще по этому loss делать backwards.

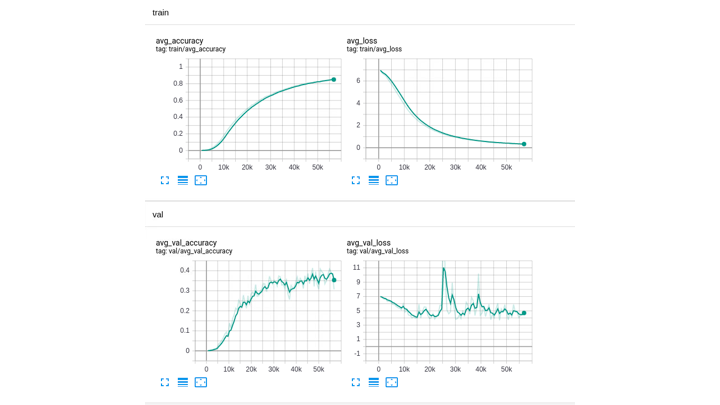
Это был один step – одна итерация. Что делать дальше: например, я бы хотел, чтобы в моем пайплайн в конце каждой epoch у меня считался average loss и average accuracy. Сделать это достаточно легко: у нас эти значения, которые мы возвращаем в конце каждой итерации, сохраняются. То есть, у нас хранится loss для каждой итерации в течение одной epoch, так что значение мы возьмем среднее. Потом то же самое с accuracy, опять же возьмем средние значения из tensorboard. Теперь мы плавно переходим к другим логгерам, здесь есть такая же штука с progressbar, о которой я говорил до этого. В этом случае я просто добавляю сюда average loss и average accuracy, то есть, в конце каждой epoch у меня в терминале будет высвечиваться, что там было на каждой epoch.
Но если мы хотим использовать не только такой текстовый логгер, но и визуализировать результаты, что нужно для этого сделать? Вот у нас есть тренировка, где закончилась одна epoch, и мы хотим, чтобы ее значение, эти average loss и average accuracy, писались в tensorboard. Делаем какой-нибудь вериболл и храним в нем поля, ключики, которые хотим записать в тот или иной логгер, в моем случае, tensorboard. Результат прописываем под ключом log. Здесь мы полностью пропускаем шаг, где нужно писать что-то вроде writer and scholar, просто указываем свое название и то или иное значение. И в логгинг мы добавляем dictionary – по сути, это уже даст нам визуализацию данных.

Сейчас расскажу поподробнее о инициализации и как её сделать. Какие существуют логгеры для инициализации? Есть MLFlow, Neptune, TensorBoard, Weights&Biases. Я сам использую TensorBoard и Weights&Biases. Логгеры достаточно легко инициализируются; то есть, у нас есть Weights&Biases логгер, мы из Lightning импортим его, а также какие-то внутренние поля, характерные для конкретного проекта, типа название папки, название проекта и так далее. А затем просто этот Weights&Biases логгер объявляем в trainer и говорим, что это наш логгер.

И теперь все, что мы подали в лого, будет автоматически синхронизироваться с этим логгером. Ровно такой же пример для tensorboard: объявляем tensorboard, у нас здесь есть логгер (про вторую строчку я расскажу на следующем слайде) и опять же в trainer просто говорим, что наш логгер — это логгер с tensorboard и будет ровно то же самое. То есть, в этом случае ничего менять не нужно, все логи работают одинаково именно в training epoch end или validation epoch end. Они все работают одинаково, по крайней мере для логов, что я использовал, но у меня есть четкое предположение, что точно так же будет и с другими. Что касается логгеров, то там все раскладывается на такие вот красивые картиночки. Все по разделам, все работает.
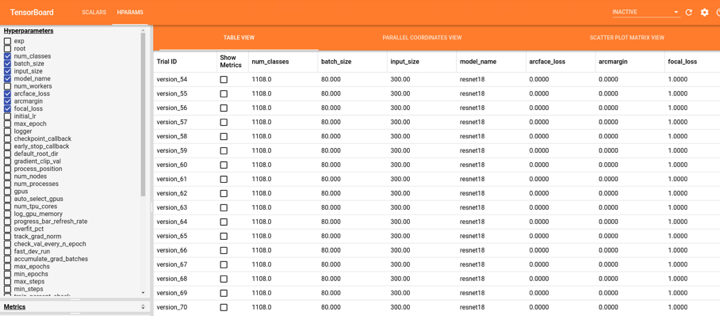
Возвращаюсь к строчке, о которой я хотел упомянуть ранее. У нас есть логгер, и пока что кодировка запускается с какими-то определенными параметрами: batch size, размер картинки, путь к дата-сет, использовать/не использовать, какой loss считать и так далее. У меня в проекте был такой parser небольшой и тут перечислена информация о loss, putsize и прочем. Что происходит? Мы эти аргументы записали, они во время выполнения командной строки появляются, и мы говорим, что у нас и по TorchLightning и trainer нужно добавить эти аргументы к нам. Аргументы мы пропарсили, объявили наш логгер, как было в предыдущем примере, и мы args записываем в наш логгер. Log hyper params не обязателен для tensorboard.

Что из этого получается? Это tensorboard, там лежат scalars, и у нас есть гипер-параметры, с которыми мы запускали конкретный эксперимент. То есть, все параметры, с которыми запускался Lightning, сохраняются. У нас есть разные возможности выбора, что можно показывать в tensorboard, это все происходит автоматически, ручной работы не требуется.
В предыдущих слайдах вы, возможно, видели такую штуку, как callback, сейчас я о ней вам расскажу. Мы хотим сохранять наши модельки, у нас сейчас не работает train loop, но есть готовые callback, которые позволяют нам выполнять определенный тип задачи во время тренировки. Допустим, мы хотим сохранить модельку. У нас есть ModelCheckpoint, он уже прописан в Lightning class, и мы объявляем там поля типа filename. Savetop помогает нам хранить лучшие веса, что спасает от переполнения диска. Также можно указать слово monitor – это значение, по которому все будет сравниваться, допустим, лучшие чекпойнты сравниваются по валидационному loss. Period — как часто делать чекпойнт, каждые пять epoch, например.
Кроме того, есть early stopping. Зачем он нужен? Допустим, вы не знаете, сколько идет тренировка, даже предположительно, и тогда вы говорите, что хотите наблюдать за валидационным loss; если каждая следующая epoch отличается менее, чем на заданную дельту, то мы делаем стоп этой тренировки. Patience – сколько эпох должно пройти, чтобы делать earlystopping.
Что нужно сделать, чтобы написать свои callback? Для того, чтобы запустить тренировку хранение чекпоинтов и early stopping, нужно прямо указать trainer, что в качестве чекпойнт callback мы хотим использовать наш callback и в качестве callback с early stopping использовать early stopping callback, который вы видели на предыдущем слайде.

Теперь перейдем к custom callback; нам нужно наследоваться от callback, который есть в Lightning, и задать условия. Допустим, в конце мы хотим сделать что-то, когда заканчивается тренировка, например, выгрузить картинки с референсами. Все наши кастомные callback передаются в trainer с ключиком callbacks. Справа указаны некоторые моменты тренировки, в которых можно использовать callback. Если вдруг случился keyboardinterrupt во время тренировки, то можно сохранить модельку. То есть, использоваться могут совершенно разные временные промежутки тренировки. Очень похоже на tensor flow, если кто с ним работал.

По поводу дополнительных фич. Lightning достаточно хорошо структурирует код: все хранится в одном месте, с красивыми названиями, у нас нет train loop, что может быть плюсом; а также логгинг в удобный терминал и в большое количество логгеров. Также из новых фич – перед тренировкой пройдет один трейновый batch и один валидационный. Это проверка того, чтобы у нас в будущем ничего не упало, например, если epoch идет несколько часов. Если тренировка упала, ее легко восстановить; просто указываем путь к чекпоинту, у нас восстанавливаются optimizer, scheduler, все логгеры, все возвращается к предыдущему состоянию.

И наконец, multi gpu trainer. На примере можно увидеть, что я использовал одну gpu, и она передается как лист с винтовыми числами. Если хотите использовать несколько gpu и не хотите их перечислять, вы говорите gpu = -1, и он будет использовать их все. Если вы говорите, gpus = [3], тогда он подключит все gpu до третьей.
Q&A:
Q: Максим, а по ощущениям, насколько строчек сократился код? Я посчитал, но у меня как-то немного получилось, optimizer убрался, форс?
А: Не критично: логгеры стали меньше занимать. Не стоит в tensorboard scolars писать. Здесь решает структура именно, не количество строчек кода, а то, что удобно знать, куда нужно смотреть, если что-нибудь сломалось.
Q: Для multi gpu распараллеливается ли data?
A: Я просто использовал одну gpu, не уверен, что знаю, что происходит с data parallel. Что-то мне подсказывает, что да, но стоит перепроверить.
Q: Максим, а ты свои callbacks писал какие-то? С принтами более-менее понятно, но что-то более сложное пробовал писать?
A: К сожалению, свои не писал. Но у меня была идея inference, предположим, сделать в конце тренировочной epoch: просто прогоняем тестовую выборку, предположим, и делаем inference в определенную папку по картинкам. В принципе, там можно что угодно придумать и с логгерами и с inference.


