
Расшифровка семинара Александра Ляшука (Xperience AI), который состоялся в июне 2020 года. Видеоверсия этого выступления, а также другие доклады доступны для просмотра на нашем youtube-канале.
В рамках сегодняшней встречи мы поговорим про трекинг-эксперименты в машинном обучении.
Прежде всего, при управлении трекинг-экспериментами мы хотим версионировать код. Для этого у нас есть git. Когда мы версионируем код, мы фиксируем нашу архитектуру, фиксы, предобработку данных и так далее. Дальше мы хотим версионировать данные, которые поступают на вход нашей сети и хранить все изменения этих данных. Для этого существует другой тул, DVC, Data Version Control. Мы можем хранить тренировочные конфиги в гите, можем хранить их при помощи DVC, можем использовать Google Spreadsheets и что-то другое. Об этом «другом» и пойдет речь.
Также мы хотим хранить метаданные, чтобы ориентироваться в наших экспериментах. Обычно это все реализовано с помощью Google Таблиц, в которые мы что-то записываем по результатам экспериментов, но это требует большой самодисциплины.
Можно ли это как-то обойти? Для этого существуют тулы для трекинга экспериментов. Их можно разделить на три категории – клауд-версии, версии 50/50 и версии in-house. Клауд-тулы – это когда у нас и код, и все данные, и результаты хранятся в облачном сервисе. Об этом мы говорить сегодня не будем. Второй тип – это 50/50, когда у нас и код, и данные могут храниться где угодно, но весь логинг осуществляется в клауде. In-house – это когда наш код и данные хранятся где угодно, но сам логинг, визуализация, тулы настраиваются нами самостоятельно.
Tensorboard
Какими качествами должен обладать идеальный тул? Во-первых, он легко устанавливается и имеет фронт-энд визуализацию. Во-вторых, логи должны быть легко передаваемы с машины на машину. Также нам бы хотелось, чтобы тул был бесплатным и поддерживался сообществом.
Очевидно, под это описание подходит Tensorboard. В частности, есть Tensorboard X, чтобы не тащить за собой Tensorflow. Легко устанавливаем ее одной командой pip3 install tensorboardX. Инициализируем summary writer, которому мы говорим имя эксперимента и папку, в которой мы хотим хранить эксперименты. Все, казалось бы, очень просто и не требует вообще никаких усилий. Необязательно быть большим специалистом в нейронных сетях, чтобы настроить Tensorboard. Фронт-энд запускается через tensorboard --log_dir experiements. Указываем директорию и видим, что там еще ничего нет, потому что мы еще ничего не успели туда записать.
Как можно использовать Tensorboard: как минимум, добавить скаляры (scalar). Помимо этого, можно добавить еще много вещей — так как мы занимаемся компьютерным зрением, мы рассмотрим добавление изображений, гистограммм, аудио, эмбедингов и так далее.
Что можно делать со скалярами? Часто в PyTorch есть функция get_loss, которая возвращает словарь со всеми посчитанными лоссами. Мы можем просто вызвать add_scalars и получить картину, когда все лоссы объединены на одной картинке.
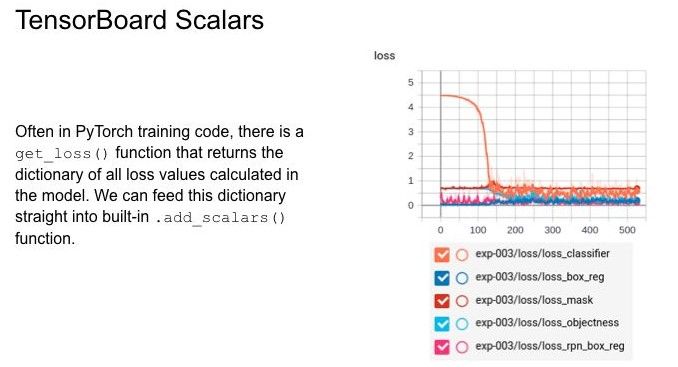
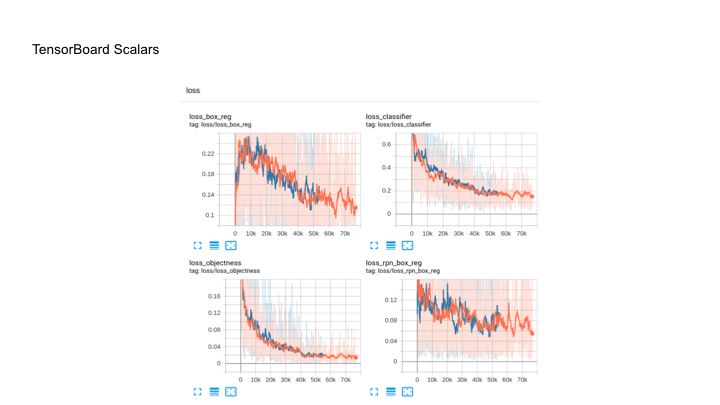
Это не очень удобно, поэтому мы можем пробежаться по циклу и добавить каждый лосс отдельно. Получается такая картина, что тоже часто неудобно. Возникает вопрос – как же объединить все на одной странице? Для этого мы берем стандартный summary writer у Tensorboard и просто добавляем в него функцию add_scalar_dict, добавляем тэг (tag=none), добавляем префикс loss/ и таким образом мы можем взять и объединить наши функции потерь. После этого берем логгер, используем кастомную функцию add_scalar_dict, добавляем туда наш dict с тэгом loss и добавляем ему итерацию. Получаем вот такую картинку, когда у нас просто под префиксом loss показаны все loss. Это намного удобнее, чем открывать каждую вкладку отдельно.
Все привыкли хранить результаты экспериментов в Google таблицах, но мы хотим автоматизировать процесс добавления метрик. Это можно сделать при помощи функции add_hparams. Можно передать туда необходимые метрики, таким образом, мы будем иметь следующую картину: у нас появится новая вкладка, помимо скаляров – это вкладка hparams. С ее помощью мы можем смотреть, как с каждой эпохой изменяется значение наших метрик. Также туда записываются вещи, которые мы передали в args, это могут быть batch_size: девайс, на котором запускается модель, и все остальное. Также он позволяет строить диаграммы, которые показывают, как метрика меняется от использования разных моделей, параметров и так далее. Когда мы работаем с задачами, связанными с компьютерным зрением, – в частности, с детекшном, – мы хотим посмотреть, как у нас от эпохи к эпохе меняются предсказания. Это тоже можно делать с использованием TensorboardX summary writer: нам нужно вызвать функцию add_image_with_boxes, добавляем "pred_images/PD- {}" для того, чтобы объединить это все в одну вкладку. Потом добавляем изображения, лейблы и боксы. Можем смотреть по каждому эксперименту, как и что меняется. Это может быть удобно для визуализации и делается это достаточно просто, вызовом одной функции.
Weight & Biases
Допустим, мы научились пользоваться Tensorboard. С помощью стороннего сервиса можно упростить работу и смотреть удаленно на метрики и потребление системных ресурсов. Weight & Biases позволяет хранить все нужные нам данные где-то отдельно. А самое главное – для этого не нужно ничего делать. Нужно просто зарегистрироваться на Weight & Biases – это бесплатно для личного пользования, вам дается безлимитное количество приватных репозиториев. Сайт выглядит как GitLab, GitHub и так далее.
Где начинается магия. Допустим, мы хотим использовать Weight & Biases, но не хотим смотреть документацию и переписывать код, а хотим перейти в браузер и смотреть с любого девайса, как у нас дела с тренировкой. Для этого нам нужно инициализировать wandb.init и передать ему конфиг (config=vars(args), и соответствующее имя эксперимента. Если мы не назовем никакое имя, оно будет генерироваться практически так же, как у Docker контейнеров. Строчка, в которой происходит вся магия – wandb.init (sync_tensorboard=True). Она дает нам возможность синхронизировать все в Weight & Biases. Надо сказать, что выглядит он намного приятнее, чем Tensorboard – и позволяет делать даже больше: например, можно увидеть запущенный эксперимент, и убивать мы его можем прямо в браузере. Помимо этого у нас хранится state нашего кода. Когда мы запускаем любой эксперимент, у нас делается коммит и он хранится.
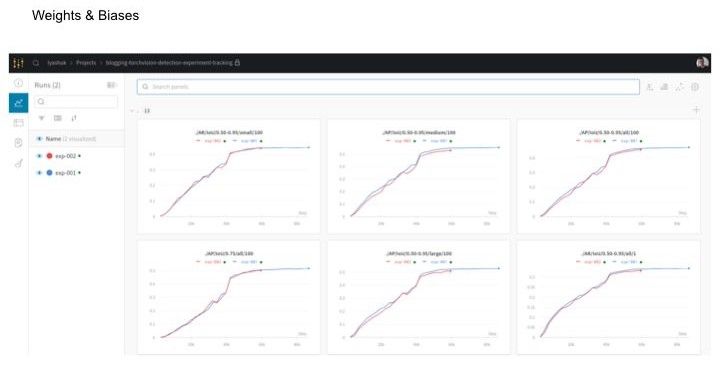
Из минусов – это невозможно сделать, если мы запускаем эксперименты в клауд-сервисах, потому что, например, в Collab у нас убьется контейнер и ничего не сохранится. Можно смотреть логи, можно осуществлять мониторинг ресурсов системы во время запуска тренировки, что тоже может быть удобно. Помимо того, что можно синхронизироваться с Tensorboard, мы можем использовать функции и методы, которые есть в самом Weight & Biases: добавить изображения с боксами, лейблы, предсказания.
Приватное решение
Теперь по поводу решений, которые могут быть приватными. Допустим, у нас есть отличная тула Weight & Biases, но очевидно, что передает все данные по сети и где-то их хранит. Предположим, что мы хотим что-то похожее. Для этого мы можем использовать Sacred + Omniboard. Штука бесплатная, опенсорсная, но немного сложная: нужно как минимум установить Docker для того, чтобы поднять Mongo, протащить ее локально, прокинуть порт и также установить через Docker Sacred. При этом синхронизация с summary writer у меня не работала – может быть, хорошо работает с Tensorflow. Мне кажется, это неудобно, потому что придется переписывать код. Здесь похуже UI, потому что опенсорс. Из плюсов – там хранится все то же самое, что и может хранить Wight & Biases, кроме системных ресурсов. Но он так же может хранить state кода, зависимости, смотрит, какие библиотеки были импортированы, и всякую такую информацию он тоже хранит. Но если мы хотим взять и визуализировать графики, придется самому писать функции для Sacred.
Q & A
Q: Имеет ли смысл устанавливать TensorboardX, когда в PyTorch есть свой?
A: Он там есть, но наличие TensorboardX позволяет быть независимым, даже от PyTorch.
Q: Я могу шарить свои эксперименты в Weight & Biases? Опубликовать?
A: Можно, в этом и плюс. Важный момент – это коммерческая компания. Если ты используешь их сервис для трекинга личных своих экспериментов, это все бесплатно. Если ты хочешь пошарить свои эксперименты с заказчиком или с какой-то командой, то нужно будет заплатить денег. Там может быть твой репозиторий. Когда ты публикуешь свои эксперименты, у тебя создается свой репозиторий, он может быть публичным, может быть приватным.
Q: Насколько такие решения готовы работать с большими объемами данных? Если, например, количество отсчетов исчисляется не сотнями, а сотнями тысяч или у нас таких треков много?
A: Tensorboard крайне медленно работает на больших объемах данных. Он съедает место на диске и так далее. Если у тебя совершенно обычная тренировка на пару миллионов итераций, то после нескольких таких тренировок у тебя место, занятое логами, начинает исчисляться гигабайтами. Зато можно передать этот еvent файл куда угодно.


