
Расшифровка семинара Александра Смокалова (Xperience AI), который состоялся в апреле 2020 года. Видеоверсия доступна для просмотра на нашем youtube-канале.
Недавно у нас был семинар, где я рассказывал про Docker и виртуальные машины (VM). Сегодня я покажу, где скачать Docker, как воспользоваться локально, а главное – как использовать для непрерывной интеграции. Кроме этого, я расскажу о том, как им пользоваться с карточками NVidia для сеток и как вообще использовать его с другим железом.
Что такое Docker и его базовые концепты
Идея, которую эксплуатирует Docker, концептуально достаточно проста. В Unix с исторических времен есть syscall chroot, который меняет файловую систему — все файлы, который он открывает, будут из той системы, которую вы ему указали. Таким образом с давних пор изолировали веб-серверы, базы данных и прочие сервисы. Docker эксплуатирует расширенную версию этой идеи. Современное юниксовое ядро позволяет управлять доступами к объектам ядра и разрешать или запрещать системные вызовы для каждого процесса в отдельности. Процесс в таком изолированном окружении не может взаимодействовать с другими процессами в системе, он про них не знает и на базе реализации ядра ОС ограничивается доступ, вызовы и все остальное. В итоге получается нечто типа VM, но без виртуализации посредственного оборудования.
Несколько слов про термины. Docker-файл (Dockerfile) – это текстовый файл, который в первую очередь описывает структуру изолированного окружения в терминах файловой системы. Docker image – это образ файловой системы, которую мы построили из Docker-файла. Docker-контейнер (Docker container) – это Docker image + процессы, запущенные в этом изолированном окружении + те файлы, которые этот процесс породили. Для того, чтобы взаимодействовать с внешним миром, Docker-контейнеры используют идею виртуальных сетей (Docker virtual network). На уровне ядра создается некоторое количество виртуальных сетевых адаптеров: этим адаптерам выдаются ip-адреса и в зависимости от настроек Docker контейнер и хост соединены либо через bridge, либо через NAT. К контейнеру, как к изолированной маленькой VM можно подмонтировать кусочек вашей локальной системы и работать с ней. В экосистеме Dockerа есть такая штука как Docker registry. Это хранилище для бинарных Docker images и набор инструментов для того, чтобы эти Docker images собирать, отправлять, получать и обслуживать.
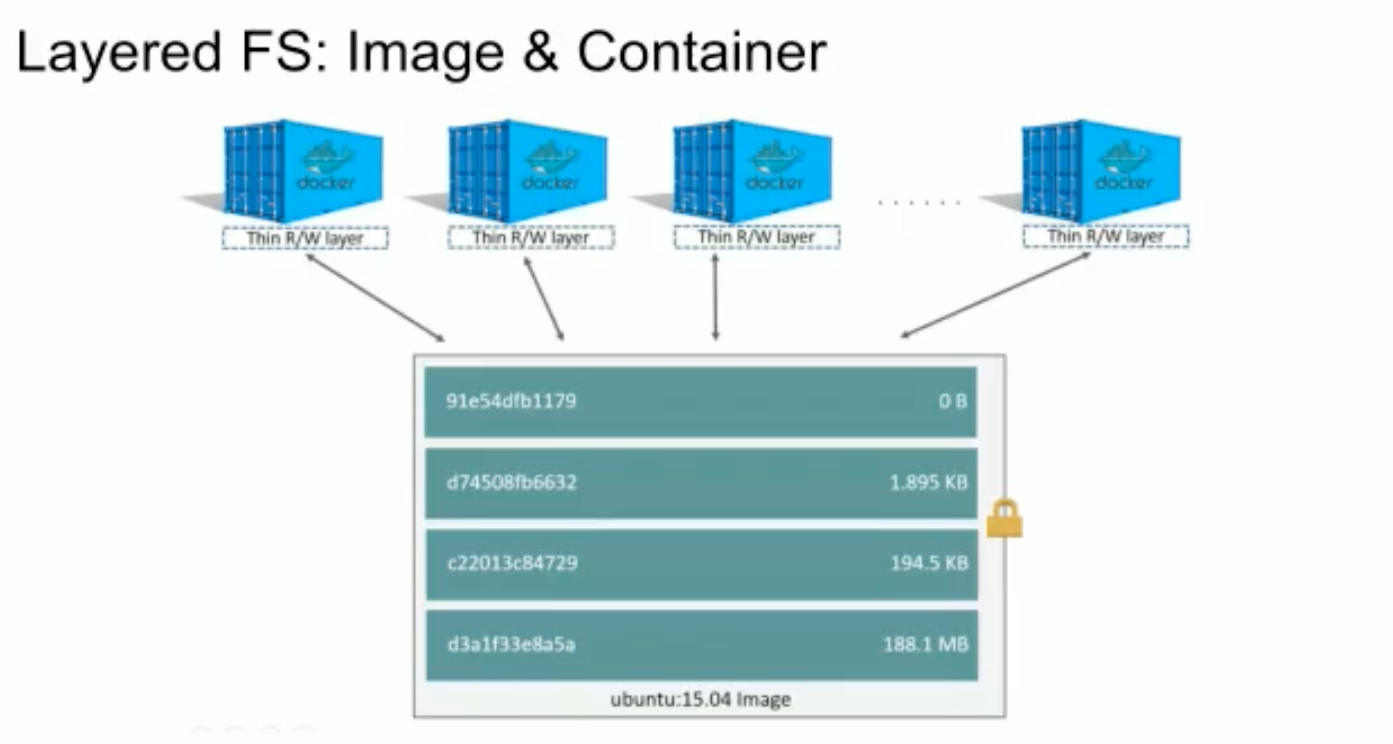
Docker использует иерархическую файловую систему, поэтому отдельные команды внутри Docker-файла хранятся на диске в виде слоев дельт, который драйвер файловой системы на ходу объединяет вместе – и с точки зрения запущенного процесса. Слои можно переименовать, у каждого свой есть хэш, к каждому слою можно повесить какой-то тэг. Вы можете наследовать друг от друга Docker images,и они будут переиспользовать кусочки друг друга. Registry тоже использует эту идею, и если у вас есть общая часть у нескольких Docker images, то она хранится один раз.
Как получить Docker и как им пользоваться
Проект Docker – это проект с открытым исходным кодом, который мы сегодня обсуждаем в контексте Линукс-систем, но он существует и для других платформ. На docker.com можно почитать инструкцию. Если вкратце, Docker предлагает добавить вам в Ubuntu сетевой репозиторий, с которым можно поставить программу Docker CE (Community Edition). После этого нужно добавить своего юзера в группу Docker, которую проект создает. Ubuntu 16-18 поддерживается в полном составе.
Сама команда Docker поддерживает такой проект Docker Hub, это а-ля GitHub, только для Docker images, для хранения бинарных сборок. Там можно зарегистрироваться, положить свои Docker images – они будут доступны для всех. Большинство проектов, так или иначе связанных с сетью и базами данных, например, веб-сервисы – они все, как правило, имеют официальный Docker image, который выложен на DockerHub. Во многих ситуациях, нет смысла изобретать свой image, можно взять готовый из хаба.
Строим Docker image
Давайте рассмотрим на примере моего маленького проекта: я покажу основные принципы работы и сделаю систему непрерывной интеграции. Проект примитивно-модельный, но его достаточно, чтобы показать базовые вещи. В свой репозиторий с кодом на питоне я положил Docker-файл.
Docker-файл выглядит следующим образом. Сначала мы уточняем, с какого места хотим начать – директива FROM, какой базовый Docker image мы используем для дальнейшего построения. Проект Canonical выкладывает базовые образы для Ubuntu сразу на Docker Hub. Дальше мы выбираем пользователя, из-под которого будут запускаться дальнейшие команды USER. RUN - это команда на выполнение цепочки. Прописываем наш environment, говорим, что поставить для питона, создаем пользователя и выбираем этого пользователя. Собственно, все! Последний шаг, который надо описать в контейнере – это точка входа. Тут можем написать – CMD bash. При старте контейнера у нас запустится bash по умолчанию. Команда docker build соберет нам наш Docker image. Сначала скачается часть, которая отвечает за from, потом Docker пройдет по всем командам – user, run и так далее, все их по цепочке выполнит и в результате выполнения каждой команды создастся новый слой, который описывает изменения внутри этого слоя. Все эти слои осядут у вас в системе, по умолчанию в /var/lib/docker. Каждый раз, когда заканчивается шаг и мы получаем результат, Docker пишет хэш каждого слоя, который у нас получился. Если мы видим надпись successfully built – значит, мы построили Docker image. Все изображения, которые у нас есть в наличии, можно перечислить командой docker images.
Мы собрали Docker image, но у него нет тэга, он никак не называется, а просто лежит в списке слоев. Мы сможем с ним оперировать только с помощью хэша, Docker build можно указать через -t название тэга. В результате у нас появилась базовая файловая система, которую мы описали в Docker-файле, со всеми файлами, которые к нам пришли из базового образа убунты, плюс то, что мы поставили – APTon и так далее. Сейчас мы можем запустить контейнер командой docker run, которой я придаю флаги -it, что значит interactive, чтобы у нас был прямой доступ. Пишем команду --rm, чтобы контейнер сразу же удалить по завершению процесса. Я указываю --entrypoint bash на случай, если у нас другая по умолчанию точка входа, но мы хотим поработать с контейнером через shell. Указываем имя контейнера (Итог: docker run -it --rm --entrypoint bash имя файла). В результате мы получили shell, который запущен внутри контейнера. Дальше мы с ним можем работать. Как только я выйду из контейнера (exit), shell завершится и контейнер система удалит автоматически. Все запущенные на текущий момент контейнеры можно увидеть командой docker ps. Если контейнер остановлен – то командой docker ps -a.
Монтируем проект и запускаем тесты
Кроме того, что мы запустили контейнер и там по умолчанию запустилась точка входа, в контейнер можно смонтировать наш проект. Прописываем опцию -v, указываем директорию на локальной файловой системе. Docker требует, чтобы все пути при монтировании были абсолютными. Это через двоеточие прописывается путь внутри контейнера. Если мы пойдем в proj, то увидим все наши файлы здесь. Обратите внимание, что у нас есть две фактически независимые файловые системы – файловая система на хосте и внутри контейнера. При создании Docker images и пользователей внутри контейнеров линуксовое ядро с ними работает по ID. У обычного пользователя идентификатор 1000, если у вас первый юзер в системе. Пользователь внутри контейнера, если он зовется user, и пользователь user на хосте – это не одно и то же, это два независимых пользователя и при записи на файловую систему в атрибутах файла будут выставляться пользователи и группа по их индексу.
Может быть такая ситуация, что пользователи внутри контейнера и пользователи снаружи не соответствуют друг другу. Например, файлы, которые пишут volume – к ним локальный пользователь доступа не имеет. Для того, чтобы с volume потом можно было работать, надо следить за правами доступа. Смонтировали проект внутри контейнера, теперь можем запустить в нем тесты. Тесты у меня просто написаны с unittest. Если я сейчас открою на хосте что-нибудь из файлов, отредактирую и сохраню, я могу снова запустить их в контейнере, то есть это не копия файлов, а смонтированный директорий.
Непрерывная интеграция
Теперь перейдем к вопросу про непрерывную интеграцию, как нам подружить всю эту конструкцию с CI и GitLab. Для начала вернемся в браузер и посмотрим, что нам предлагает GitLab. Сам проект Docker предлагает Docker registry, надстройку над registry с удобствами предлагает, например, проект Harbour. Также есть hub.docker.com – это готовый registry, если вы не хотите платить, можете выкладывать туда. Если вам нужна приватную часть, вы можете заплатить ребятам и у вас будут приватные registry.
Также Docker registry предоставляет GitLab. У каждого проекта в GitLab есть раздел Packages – Container Registry. Получается, что маленькое registry приклеено к каждому проекту в GitLab, если это включено в ваших настройках. Технически поддержку registry можно на уровне GitLab выключить, но по умолчанию она для всех включена. Здесь мы увидим список всех Docker images, которые нам доступны, в том числе с тэгами. Если мы при построении указывали просто имя Docker image, то он по умолчанию создается с тегом latest. Тэг указывается через двоеточие. Для одного и того же образа может существовать несколько версий с разными тэгами. В одном registry под одним именем можно хранить несколько версий одного и того же образа.
Для всех Docker images, которые хранятся не на hub.docker.com, в имени images указывается полный путь с именем сервера. С точки зрения GitLab это registry.gitlab.com/имяпользователя/названиепроекта. Если у вас вложенная группа в GitLab, значит, все группы будут отображаться здесь. Для того, чтобы работать с другим registry, на него надо залогиниться. Например, пишем docker login, указываем registry.gitlab.com, дальше вводим логин и пароль, они соответствуют логину и паролю на GitLab. Docker локально хранит токен аутентификации для registry и все pull и push вызовы будут с идентификацией.
Когда мы строим Docker image, мы указываем тэг. У меня, в частности, тэг содержит registry.gitlab.com с путем, где находится репозиторий. После того, как мы его построили мы его можем запушить в Docker registry командой docker push. Все пулл пуш команды, все обмены по сети проходят послойно и инкрементально. Те слои, которые уже в Docker registry существовали, для них проверяются хэши и они не перезаливаются. Когда вы пулите обратно, происходит то же самое.
После того, как мы запушили наш Docker image, у нас есть энвайронмент для того, чтобы запускать непрерывную интеграцию. Для того, чтобы описывать непрерывную интеграцию, мы создаем репозиторий файла .gitlab-ci.yml – это yml файл, который в простом декларативном стиле описывает, как устроен пайплайн непрерывной интеграции. Первая строчка – это Docker image. Указан список стадий, которые мы хотим иметь в нашем пайплайне непрерывной интеграции. Далее для каждой стадии описываем команды, которые мы выполняем. В нашем случае мы просто запускаем юнит-тест. Что происходит в моем варианте – GitLab проверяет наличие файла в ваших бранчах с названием .gitlab-ci.yml. Каждый раз, когда вы вносите изменения в этот бранч, если там такой файл есть – он перечитывается. По умолчанию CI пайплайн применяется для всех веток, где есть этот файл. Вы поменяли ветку – побежал пайплайн и его статус будет видно в GitLab.
Как работает интеграция со стороны GitLab
В тех проектах на GitLab, в которых есть CI/CD, слева появляется кнопочка CI/CD с ракетой, с разделом Pipelines. Здесь находится список всех запущенных задач, которые запускал CI. Там, где пробег соответствует последнему коммиту ветки, появляется значок latest. Если стадий много и есть элементы, которые выполняются параллельно, то рисуется большой граф, что за чем выполнялось, на каждую стадию можно нажать, посмотреть, что происходило. В нашей ситуации запустился GitLab сервер, нашел подходящий воркер, на котором запускать эту задачу, скачал Docker image, который мы указали в разделе image. Дальше он создал контейнер, запустил в нем shell, запустил Git и выкачал репозиторий, ту ветку, в которой запускается CI. Потом он исполнил все команды, которые указаны в yml файле и указал статус, что все хорошо. Клонирование репозитория, изъятие веток и так далее GitLab делает самостоятельно. Он сам управляет правами доступа, SSH ключами, логином, паролем и так далее. Статус задачи GitLab определяет по return-коду. Если скрипт-программа возвращает 0, значит, она выполнена успешно. Если программа вернула не ноль, значит, считается, что что-то пошло не так, шаг в пайплайне покраснеет.
Как интегрировать Docker с софтом от NVidia
Если мы откроем в GitLab обзор репозитория, то у некоторых коммитов появляется зеленый или красный флажок, который указывает на статус непрерывной интеграции. На него можно нажать, посмотреть, что когда проходило.
GitLab предоставляет очень небольшое количество машинного времени для цели непрерывной интеграции бесплатно. Если вы пойдете в раздел настройки – CI/CD, то здесь есть раздел Runners, сюда можно добавить свою машину, а можно воспользоваться Shared Runners, которые предлагает GitLab.
Еще одно техническое замечание – у GitLab подключение происходит не от сервера к воркеру, а от воркера к серверу. Технически воркер может стоять где угодно, хоть дома под столом. Если воркер может подсоединиться к серверу – значит, система работает. Значит, вам не надо иметь статический ip, прямой доступ с GitLab на вашу машину, DNS-имя и всякое другое.
Давайте посмотрим, как расширить наш CI и как использовать оборудование NVidia. По умолчанию Docker изолирует все оборудование, которое у вас есть в системе. Если мы запустим Docker контейнер и посмотрим, что у него в /dev, в деве находится несколько устройств общего назначения и монтируются файлы с вашего хоста типо /proc/cpuinfo, чтобы описывать ваше оборудование. Ни видеокарточки, ни usb устройства, ни диски, ни общая память в Docker контейнере недоступны, они изолируется средствами Dockerа и линуксового ядра. Это можно изменить.
Если у вас устройство имеет файл в деве и ваша программа с ним работает как с псевдофайлом, то эти устройства можно смонтировать внутрь Docker контейнера при старте. Для этого достаточно указать опцию --device и аналогично опцию –v. Указываем псевдофайл на хостовой файловой системе, :псевдофайл внутри Docker контейнера и теперь все программы, которые знают про него, могут его использовать. Важный нюанс – обязательно следите за правами доступа. Если все гладко и хорошо, то таким образом можно смонтировать большинство устройств внутрь Docker контейнера.
Второй способ – использовать флаг --privileged. Он включает привилегированный режим для Docker контейнеров и контейнеру становится доступно все, что есть на хосте, как будто бы это ваш самый обычный локальный процесс, но с другой файловой системой. Таким образом, в privileged режиме у вас в контейнере появится все ваши CPU, usb устройства, shared memory и прочие другие системные вещи.
Кроме этого, Docker позволяет доставлять дополнительные рантаймы, дополнительные плагины, которые управляют оборудованием. В частности, NVidia предлагает свой docker runtime, который позволяет подключать NVidia GPU внутрь контейнера. Если у вас несколько GPU, то ими можно управлять. Они будут работать независимо друг от друга. Сам проект от NVidia – open source. NVidia Container Runtime живет на GitHub, здесь есть подробная инструкция, где взять и как поставить. Отдельно на странице документации есть табличка про то, какие конфигурации поддерживаются – есть версии для Ubuntu, Debian, Red Hat.
Как работает Runtime. У меня на машине стоит сейчас карточка GeForce GTX650, NVidia ее замечательно видит. Я в Docker run указываю в качестве рантайма --runtime=nvidia. nvidia/cuda - это Docker image Docker Hub от NVidia. nvidia-smi – это команда, которой он перезапустится. Точно такой же вывод, как и на хосте. Например, если у вас есть тренировка нейронной сети или inference нейронной сети, которая запускается на GPU, вы можете поставить NVidia рантайм и запускаться в контейнерах, передавать Docker images с хоста на хост, перезапускаться на другом месте.
Обратите внимание, версия драйвера – это модуль ядра. Следовательно, если вы переносите Docker image с хоста на хост, то версия драйвера может меняться и вместе с ним может меняться поведение.По умолчанию возможности, которые доступны пользователю, ограничены. В частности, запрещено использовать ptrace и средства отладки. Но с помощью флажков Docker рана можно разрешить отладчики и отлаживать программу сразу внутри контейнера, если она у вас таким образом запущена. Если мы запустим нашу программу, контейнер с ним, я пишу в строке -u 0, то есть юзер 0, то бишь root, по умолчанию он запустится с рутом. Тогда я могу поставить сюда apt get update. Например, strace (apt-get install strace). Если я поставлю его и попробую запустить что-нибудь (например, strace ls), стрейс у меня работает от рута. Если делать то же самое без выбора юзера root, то по умолчанию доступ будет запрещен, стрейс ничего полезного не покажет.
Как интегрировать Docker с другим железом
К моей машине подсоединено устройство – отладчик от Olimex, JTAG адаптер. Его видно на моей хостовой системе через lsusb. Если мы посмотрим в ls /dev, то по умолчанию ничего нет. Никакого адаптера, никаких устройств внутри контейнера не видно. Но если мы запустим контейнер в привилегированном режиме, то все устройства, которые есть у меня на хосте, есть и здесь, в том числе ttyUSB0 – это тот самый отладчик. В привилегированном режиме все устройства доступны и можно запускать процессы, которые работают с оборудованием. Так же ситуация работает с устройствами типа JTAG, с серийными интерфейсами, которые UART и все то же самое работает с GPU Intel, Nvidia, AMD и так далее. А если вы запускаете без NVidia Container Runtime, но просто с опцией privileged, значит, устройство доступно, вам надо поставить рантайм в библиотеки внутри контейнера, а на хосте поставить драйвер ядра, и вы сможете использовать CUDA, OpenSL, все, что вам надо. То же касается проекта OpenVINO.
Последнее замечание по поводу запуска на разных машинах. Docker монтирует файл /proc/cpuinfo с хоста. Соответственно, cpuinfo на хосте и в контейнерах одинаковый. Из-за этого возникают интересные коллизии. В Docker есть набор опций --cpu, которые позволяют ограничивать количество CPU ресурсов для контейнера. Это разруливается на уровне ядра. Ядро ограничивает количество квантов времени, которое выделяется процессом в этом контейнере и все это работает замечательно, пока на сцену не выходят параллельные фреймворки типа NPI, TBB, и подобных им. Они ходят, проверяют системы, количество ядер, доступные системе, порождают потоки по количеству ядер. Если у вас большой толстый сервер, в котором 54 ядра, вы приходите, запускаете 10 контейнеров и каждому выдаете по 5 ядер – снаружи это выглядит хорошо. Внутри же каждый из контейнеров порождает по 54 нитки, делит задачу на 54 части, ставит их дружно в очередь, в этот момент планировщик начинает раздавать задачи согласно приоритетам и квотам. Про это надо знать, особенно если вы запускаете что-то в продакшн. Проблему эту можно обойти в некоторых ситуациях – в OpenCV в 4.3 попал патч, который работает умнее и высчитывает количество доступных процессов не просто из /proc/cpuinfo, а уже с учетом системы контейнеризации. В OpenMPI количество поток, порождаемых ниток можно ограничивать через энвайронмент и это стоит делать. Это болячка, на которую натыкаются не очень часто, но она неприятно стреляет в ногу.
Q&A
Q: Как замаунтить конкретный девайс? Например, я хочу подключить вебку, но я не хочу делать режим privilege.
A: Опция --device /dev/ttyUSB0:/dev/ttyUSB0. У нас в контейнере появляется только она. Следите за правами доступа. Современные консольные утилиты подписывают имена, а файлы системы хранит группы и юзеры не этими именами, а айди. С помощью обычного ls можно посмотреть проверить внутри контейнера и вне, сразу будет видно, что вы можете, что вы не можете.
Q: Как сделать так, чтобы девайсы были видны в момент Docker билд? Допустим, я хочу сделать свой энвайронмент. В этом энвайронменте я знаю, что у меня есть CUDA. Соответственно, я не могу его сбилдить, потому что во время билда у меня не видно CUDA, а у меня в моем энвайронменте есть какие то библиотеки из requirements, которые хорошо ставятся и два сторонних сабмодуля, которые собираются, CPU версия, если доступна CPU и CUDA версия, если доступна CUDA. Я не нашел простого решения.
A: Это немножко нарушает концепцию Dockerа. Идея Dockerа в том, что вы один раз на своей машине собираете проект в Docker image, пушите его в registry, пулите его на том хосте, на котором он будет запускаться и там его запускаете. Теоретически, Docker задуман на переносимые imageи. Завязываться на то, что во время билда у вас есть конкретная CUDA – это изначально плохая затея. Возможно, это нужно в узких кейсах, но обычно предполагается, что все максимально общее и однообразное, чтобы это можно было собрать и запустить на разных машинах. В вашей ситуации кроме как попробовать NVidia рантайм я ничего предложить не могу.
Q: Имеет ли смысл какую-то логику помимо тестов выносить в CI? Что можно встраивать в CI помимо тестов?
A: Все, что угодно. CI – это средство для того, чтобы нести баги в репозиторий. Чем больше ты их поставишь, тем лучше, при условии, что они выполняются за разумное время. Дальше – на ваш вкус. К CI/CD пайплайнам можно прикладывать артефакты, инструкция есть в yml файле.


