
Расшифровка семинара Ильи Контаева (Xperience AI), который состоялся в апреле 2020 года. Видеоверсия доступна для просмотра на нашем youtube-канале.
Сегодня речь пойдет про CenterTrack. Это модель на базе CenterNet, которая пытается объединить задачу детектирования и tracking. Сначала я немного расскажу про tracking – что это за задача, какие есть к ней подходы. Потом подробнее рассмотрим сам CenterNet. Статья про CenterTrack вышла буквально в начале месяца. Я сейчас как раз занимаюсь задачей tracking и до этого несколько месяцев занимался CenterNet, поэтому мне стало интересно, что интересного предлагают авторы.
Tracking by detection
Задача tracking ставится так. У нас есть некоторые объекты, которым мы присваиваем ID. Их необходимо присваивать в потоке фреймов – обычно это либо видео, либо поток с камеры. Мы хотим сопоставлять ID объектов в новых фреймах со старыми. В целом, эту задачу можно решать для разных объектов с несколькими классами, но так как это довольно сложно, мы делали tracking и detection для людей. Поэтому иногда я буду говорить про общие объекты, а иногда – конкретно про людей, в зависимости от контекста.
Главный практический подход, который все используют – это tracking by detection. По сути, мы разбиваем эту задачу на две. Сначала мы используем какой-то трекер – неважно какой, двухстадийный или быстрый, – и после этого используем отдельную модель для самого tracking. Классическим примером является модель SORT. Это модель, которая строится на двух классических алгоритмах. Первый – это фильтры Калмана, которые позволяют отслеживать состояние объектов во времени, учитывать их скорость, отслеживать изменение объекта во времени и пространстве. Второе – это Венгерский алгоритм, так называемая «задача о назначениях».
У нас есть два двудольных графа. На первом графе расположены ID объектов предыдущего фрейма, а на втором графе – ID текущего. Мы хотим сопоставить, как они соотносятся. Это работающий алгоритм, у него есть реализация на питоне, которую все используют. Когда начали больше использовать нейронки, прикрутили дополнительный feature extractor, который позволяет получать embeddings для людей и сравнивать эти embeddings через косинусное расстояние. В теории это должно немножко улучшать результаты, но на практике, как показали наши тесты, не все так хорошо. Сложность в том, что если у нас очень много людей в кадре, для каждого из них мы должны вычислить свой embedding, прогнать через сетку, и задача становится довольно сложной с точки зрения вычислений. В real-time это будет не так хорошо работать.
CenterNet
Основную идею можно описать так: у нас есть bounding boxes и из этих боксов мы можем получить центр нашего объекта. Получив этот центр, мы можем решать не задачу detection с предсказанием четырех координат и класса, как обычно, а просто находить такие точки и из них потом регрессировать наши bounding boxes. Стоит сказать, что эта идея появилась параллельно – существует и другой CenterNet, который основан на модели CornerNet. Это другая модель, не стоит их путать. Я буду говорить про CenterNet, который основан на идее objects as points. В этой модели мы хотим получить некоторое представление, которое называется heatmap, которая используется также в задаче key point estimation. Идейно это некоторое gray scale представление нашей изначальной картинки, где мы выделяем наши объекты в виде точек.
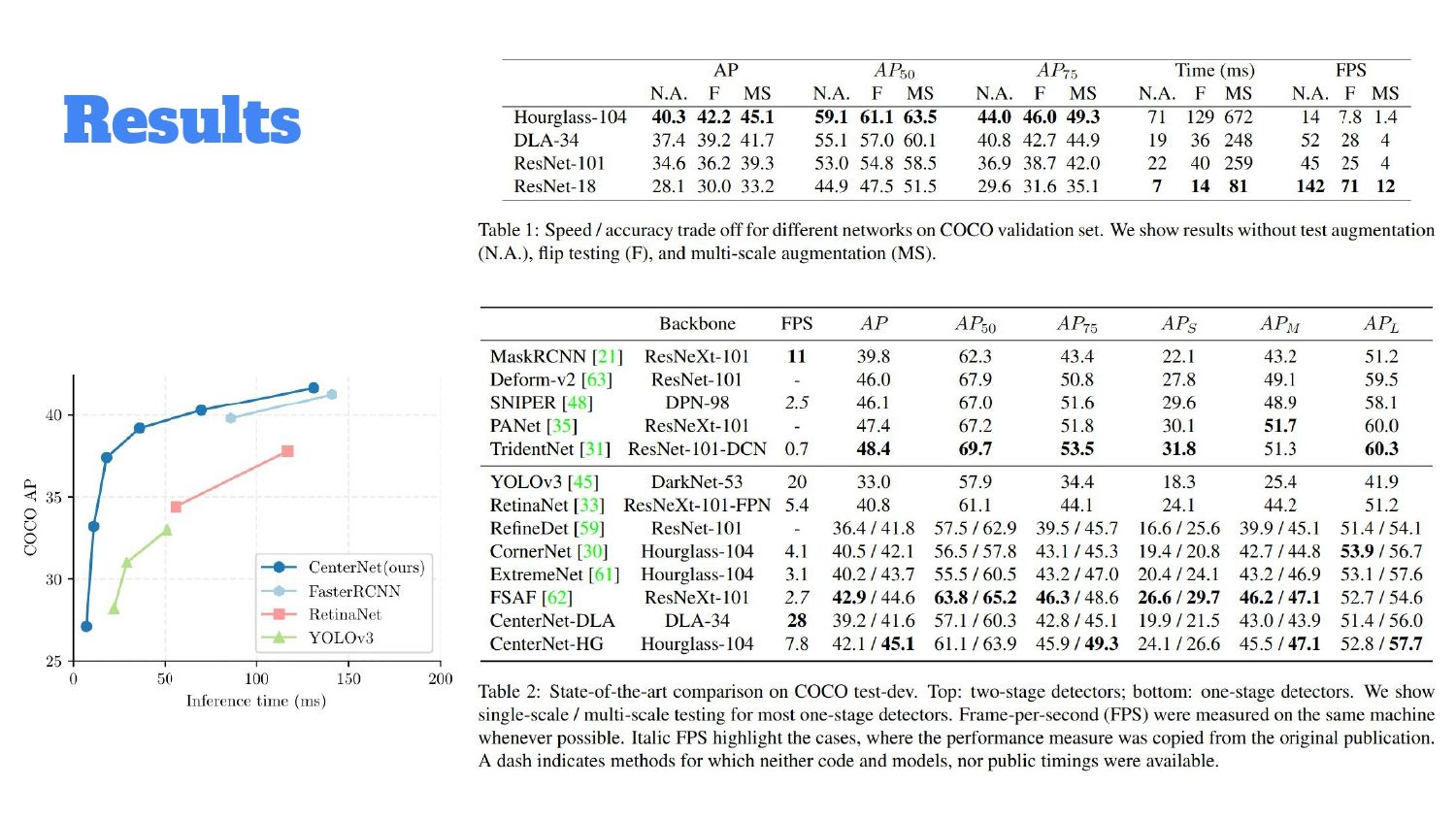
В оригинальной статье авторы использовали Hourglass, DLA и два варианта ResNet – ResNet 18 и ResNet 101. Hourglass – это «жирная» сетка, которая заточена под задачу key point estimation и показывает наилучший результат, но она не имеет ничего общего с real-time задачами. DLA по результатам – это trade-off, не самая мейнстримная архитектура. Она использует похожие идеи, например, FPN (Feature Pyramid Networks), но там чуть более сложно агрегируются фичи. Если честно, я с этой архитектурой до этого особо не сталкивался. В нашей реализации мы использовали GhostNet, это быстрый BackBone. У нас была задача сделать быстрый детектор, мы поискали, какие вообще существуют подходы, и на практике нам показалось, что это хороший BackBone для быстрого детектора.
Как работает CenterNet
Поговорим о работе CenterNet: как мы преобразуем наши таргеты и что хотим получить. В нашем случае это heatmap – gray scale изображение, от нуля до единицы, где число каналов – по сути число классов. Помимо самой heatmap, у нас будут другие объекты, но сначала нужно разобраться, как получить heatmap. Мы прогоняем изначальную картинку через BackBone и таким образом мы можем уменьшить размерность изначальной картинки. В оригинальной статье получается heatmap в четыре раза меньше, чем наша изначальная картинка. Сначала прогоняем часть через Downsample, потом есть некоторый upcycling. В зависимости от архитектуры это либо просто deconvolution, либо вот как Hourglass – encoder decoder архитектура. На выходе есть какая-то heatmap и мы можем опционально немного ее улучшить с помощью преобразования через Гауссовский Kernel (gaussian kernel), который нам позволит размазать наши точки более, сделать их менее плотными, размазать их немного по нашей heatmap. Это делается с помощью такого преобразования.
Внизу есть стандартное отклонение, оно учитывает радиус нашего объекта. Преобразование нашей точки будет больше, если наш объект изначально был больше и будет меньше, если объект маленький. Для самой сети у нас есть три функции loss – мы решаем три задачи одновременно. Первая – это задача классификации по heatmap. В оригинальной статье используется Focal Loss, то есть некоторое улучшение cross entropy (перекрестной энтропии), которое позволяет меньше штрафовать те точки, которые и так хорошо угадываются, и больше штрафовать точки, которые угадываются хуже. Также есть loss на размер объекта – на самом деле мы по сути предсказываем две координаты, это широта-высота. У нас по сути три отдельных «головы» помимо нашего основного BackBone – сверху у нас три небольших сверточных нейронки, буквально несколько слоев. Помимо размера, мы хотим немножко скорректировать наши предсказания, так как мы делаем downsampling в heatmap, мы хотим небольшую погрешность тоже учитывать. С помощью функции L1 loss мы предсказываем Offset. Все три loss вместе взвешиваются. Наибольший вклад вносит первый loss, который мы предсказываем для heatmap.
Декодируем
После получения такой heatmap, мы хотим из нее получить bounding boxes. Как это можно сделать: мы используем pulling, например, max pulling 3х3, чтобы выделить top k peaks на heatmap. В оригинальной статье k = 100, но на самом деле это гиперпараметр, его можно менять. Необходимо выделить основные пики и каждый пик – это наш confidence объекта. Мы его сможем транжировать и преобразовать в привычное представление, bounding box confidence для каждого объекта. Bounding box высчитывается также благодаря тому, что мы посчитали размер объекта и его отступ. Эта дельта – наш отступ. Как вы видите, на моменте декодинга мы не используем какие-то сторонние алгоритмы вроде NMS (Non-maximum Suppression), как принято делать в классических детекторах. Используем только max pulling, что довольно упрощает наши вычисления на момент inference, потому что нам не нужно дополнительно использовать сложные надстройки. В этом большой плюс CenterNet. Также ненужно заранее отсчитывать и задавать anchor boxes – стадия постпроцессинга довольно простая.

Сравнение результатов
Давайте посмотрим на сравнение BackBones, которые они использовали – их было четыре. Стоит упомянуть, что время inference кажется быстрым – 14 миллисекунд. На самом деле, это на каком-то из TITAN, кажется TITAN X. Это inference на GPU и скажем так, довольно странно мерить такое, если вы хотите делать real-time сетку только на GPU. DLA предлагает trade-off и по качеству, и по скорости, а Hourglass показывает наилучшее качество, но при этом работает очень медленно. Также они сравнивают результаты с другими архитектурами, как двухстадийными, так и one-stage детекторами типа YOLO. Если брать кейс real-time детектора, то первое, что пришло нам в голову – попробовать другие BackBone, которые заточены именно под эту задачу.
Как работает CenterTrack
Сам CenterTrack – небольшая надстройка, в которой добавляются потоки фреймов, расположенные во времени. Например, каждые 0.5 секунд нам приходят треки, мы так же предсказываем наши поинты, но помимо того, что сделано раньше, мы к тому же хотим задавать ID для каждой точки. Наш объект уже представлен в виде такой четверки – это его точка, его размер, confidence и ID. Наша задача – задать такую же четверку для приходящих новых фреймов, сопоставляя их с предыдущими.
Что изменилось? Авторы сделали еще одну голову, которая добавляет смещение. Это похоже на то, как считается offset, только offset между фреймами. На вход приходит не одна картинка, а картинка текущего фрейма, картинка предыдущего фрейма и heatmap после постпроцессинга, где есть объекты с более высоким confidence. В оригинальной статье авторы выбирают довольно большой confidence – 0.5. Мы хотим предсказывать смещение, которое произошло между точками. После этого авторы используют «жадный» алгоритм для того, чтобы сопоставлять эти точки между собой. У меня есть большие сомнения в качестве работы алгоритма, потому что они ничего особо не предлагают и лишь фиксируют радиус. Внутри этого радиуса авторы берут точку с наибольшим confidence и потом по расстоянию внутри радиуса. Сам радиус считается как геометрическое среднее между шириной и высотой. В конце статьи есть псевдокод этого алгоритма.
Способы аугментации heatmap
Еще одна идея авторов статьи – аугментировать heatmap, которая приходит на вход. Если ее не аугментировать, то сеть очень быстро переобучается и просто предсказывает ту же самую heatmap. Это, по сути, аугментация/регуляризация, которая позволяет нам научиться тренировать трекер. Тут три пункта, первый – это гауссовский шум (Gaussian noise) для каждой точки. С некоторой вероятностью мы накладываем небольшой шум на нашу уже предсказанную точку. Второе – это добавление false-positives. Здесь мы также задаем некоторую лямбду. Третье – это добавление false-negatives. Они посчитали статистику на дата-сете в целом false-positives и false-negatives на CenterNet и взяли лямбды как гиперпараметры. Таким образом мы довольно неплохо аугментируем уже существующую heatmap и это позволяет улучшить качество. Без этого модель не учится.

Далее будет сравнение – они пробовали без этого и результат получился значительно хуже. Кроме этого, авторы берут не только предыдущий фрейм, а фреймы в диапазоне некоторого небольшого окна. Естественно, на inference это уже будет в потоке, на стадии обучения. Авторы так по сути аугментируют свой дата-сет. На самом деле, они предложили тренировку не только на видео, но и на классическом размеченном треке: попробовали просто учиться на статическом датасете для detection, используя аугментацию из разряда scaling, rotation, transformed. У них получилось эмулировать сдвиги точек, которых было достаточно, чтобы «выучить» довольно хороший трекер. Удивительно, что не имея разметки для tracking, можно что-то вообще подобное выучить, потому что делать разметку для tracking – очень дорого и значительно сложнее, чем для detection. Если можно выучить пусть даже с чуть худшим качеством трекер, не имея разметки – это большой плюс для такого рода модели и как утверждают авторы, у них это получилось.
Сравнение результатов
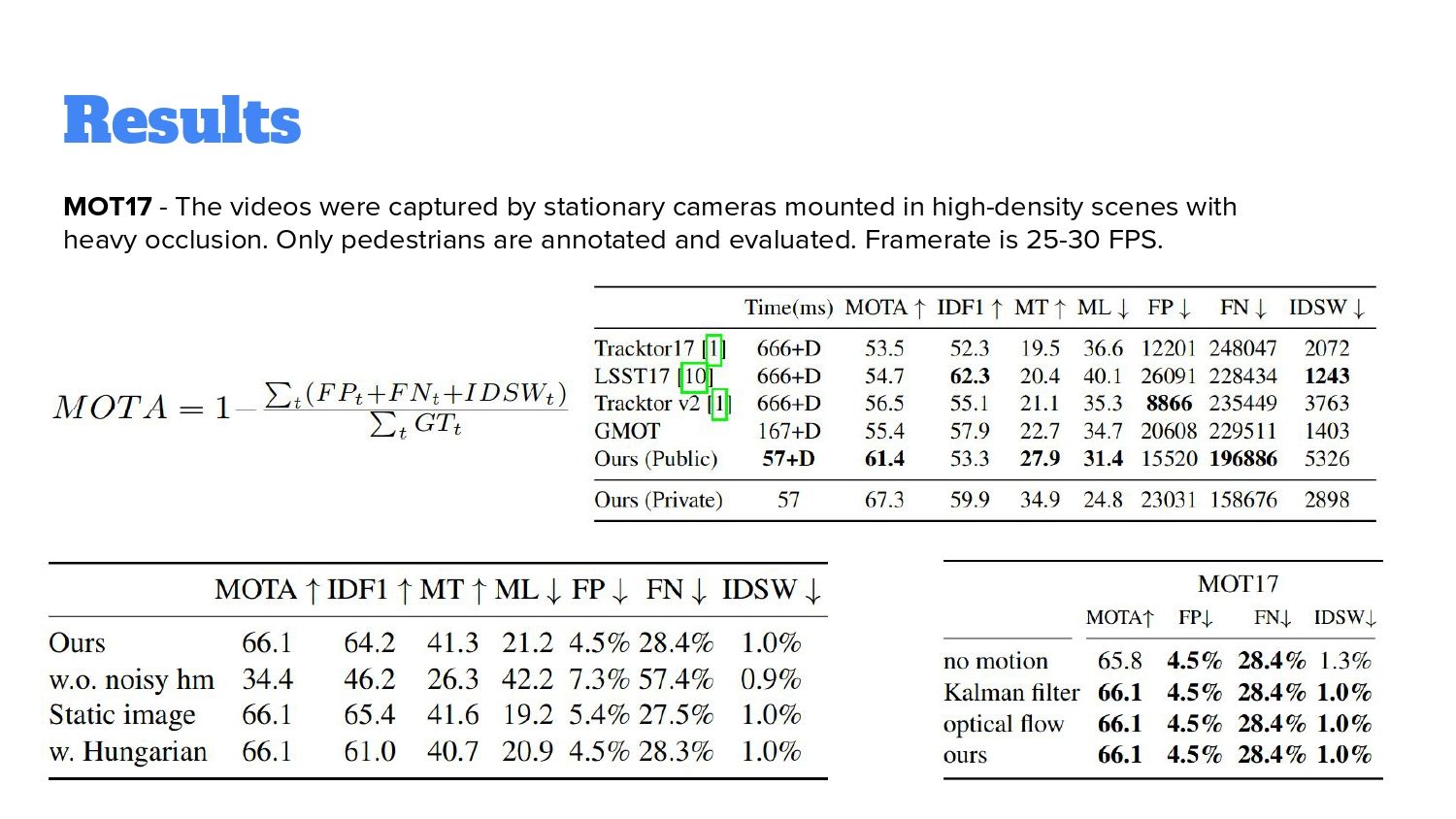
Авторы сравнивали результаты на трех дата-сетах. Первый – MOT17, съемки с камер людей в разных сценариях, в основном в городах, с разным углом обзора. Еще у них были сеты KITTI и nuScenes. KITTI – по сути камера, прикрепленная к капоту машины. nuScenes они сравнивают с одной моделью, что не особо репрезентативно. Что можно заметить – работают быстрее значительно, чем остальные.
Помимо самого benchmark, они померили другие варианты. Во-первых, пробовали учить без аугментации heatmap и по результатам сразу идет жесткая просадка, нейросеть плохо учится. Кроме этого, авторы попробовали прикрутить Венгерский алгоритм для сравнения со своим подходом – разницы нет никакой. Еще авторы попробовали разные варианты предсказывания именно motion prediction – как объект изменяется. На MOT17 никакой разницы. Если посмотреть на другие датасеты, на KITTY, то разница есть, там их подход показывает результаты получше, чем Kalman. С чем это связано – я не знаю.
Краткое резюме
- Архитектура простая – тот же CenterNet, просто меняется число каналов на входе и выходе;
- Работает в онлайне, не нужно накапливать какие-то кэши. Локальный дизайн, который работает в небольшом окне, но может быть плюсом, если мы хотим real-time кейс. Если взять быстрый BackBone, то это подходящий вариант;
- Аугментации нужны, без них нейросеть не учится;
- Авторы утверждают, что сети могут тренироваться на статических изображениях –это странно, но если это работает, то это очень большой плюс;
- Делать свою разметку для tracking очень дорого и если бы была возможность использовать разметку для detection – было бы отлично;
- Венгерский алгоритм и Kalman в этой архитектуре разницу не делает. Это интересно, потому что предыдущие решения так или иначе опирались на эти два подхода;
- Трекер получается слишком локальным и не запоминает объекты, которые накладываются друг на друга или появляются в кадре, а потом исчезают. Это будет плохо работать, поэтому нужны дополнительные решения. Одно из таких – авторы добавляют re-ID голову, но весь последующий tracking использует Kalman и Венгерский алгоритм для matching. Было бы интересно объединить эти две идеи – прикрутить именно в CenterTrack re-ID сетку и посмотреть, как будет это вместе обучаться.
Q&A
Q: Вы попробовали данную технологию. Каковы впечатления, насколько хорошо это работает?
А: Как детектор – в принципе нормально, но мы взяли другой BackBone. Плюс CenterNet в том, что он довольно простой в написании и у него простой постпроцессинг относительно YOLO. Вы сами можете попробовать, но в оригинальном репозитории слишком много всего, он решает не только задачи детекции. В CenterNet расширяют задачу, там есть и key point estimation, и pose estimation, и в 3D bounding boxes предсказывают. Там сразу куча задач, поэтому репозиторий получается довольно громоздким. Что-то для себя вычленить из этого можно, или внутри него тоже можно поучить. Мы переписали под себя.
Q: Ты сказал, что работаешь над tracking, именно используя эту сеть. Ты пытаешься интегрировать именно эти embeddings?
A: Пока нет. У нас просто есть отдельный детектор (CenterNet) отдельный трекер, в данный момент это DeepSORT. Но в начале месяца появились две такие статьи, которые говорят, что можно это соединить. Мы еще не дошли до того, чтобы это попробовать. Я запускал inference на той реализации, которую они предлагают. Посмотрел, как это на видео работает – неплохо, но не прям огонь. Проблема в том, что для того, чтобы перенести это в нашу имплементацию, нужно какое-то время, а внутри их имплементации это делать не хочется, потому что у нас есть свой отдельный CenterNet и нам не хочется работать в их репозитории. Но попробовать стоит. Самое главное – хотелось бы протестировать, насколько оно реально учится на статических дата-сетах.


